Chapitre 10 Modèles mixtes pour données structurées
10.1 Généralités
Les données sont structurées lorsque les observations partagent des caractéristiques communes. Les observations provenant d’un même regroupement sont habituellement « plus semblables ». Elles sont plus semblables parce que les observations partagent un environnement commun (e.g., un enclos), un espace commun (e.g., topographie), un regroupement temporel (e.g., des mesures répétées sur un même individu). Cette structure résulte souvent de votre échantillonnage. Par exemple, si vous échantillonez les 4 glandes mammaires de chacune des vaches de 30 troupeaux, vous devrez probablement prendre en compte le fait que les glandes mammaires sont regroupées par vache qui, elles-mêmes sont regroupées par troupeau. Les observations, dans ce cas, ne sont plus indépendantes les unes des autres (une condition essentielle pour plusieurs approches statistiques).
Si on ignore le regroupement des données lors des analyses statistiques, les erreurs types des paramètres seront souvent trop petites pour les prédicteurs au niveau du groupe, mais parfois trop grandes pour les prédicteurs au niveau individuel et un poids déraisonnable pourrait être attribué aux groupes les plus larges. Un exemple de données structurée est illustré dans la figure suivante.

Exemple de structure de données (hiérarchique). Les différents prédicteurs d’intérêt et la variable dépendante (production) sont indiqués pour chacun des niveaux de la hiérarchie.
Les modèles mixtes (mixed models) « prolongent » les modèles de régression linéaire et les modèles de régression linéaire généralisés pour prendre en considération, lors des analyses statistiques, le regroupement des données. On les dit « mixtes » parce qu’ils comprennent à la fois des effets fixes (les prédicteurs) et aléatoires (des intercepts et/ou des pentes aléatoires). On les appelle aussi modèles à effets aléatoires (random effects models) ou modèles à variance groupée (variance component models). Les modèles multi-niveaux ou hiérarchiques sont des cas particuliers des modèles mixtes où chaque niveau est parfaitement imbriqué dans le niveau supérieur (comme à la figure précédente).
Dans R, plusieurs librairies ont été conçues spécifiquement pour réaliser les différents modèles mixtes, les librairies nlme et lme4 sont probablement les plus utilisées. Brièvement:
- La librairie nlme ne pourra être utilisée que pour les modèles linéaires mixtes (i.e., les modèles où la variable dépendante est quantitative et normalement distribuée, mais où des regroupements d’observations doivent être pris en compte);
- La librairie lme4 permettra de réaliser les modèles linéaires généralisés mixtes (i.e., les modèles où la variable dépendante peut être binaire, un compte d’événements, ou autre, et permettant de choisir différentes fonction de lien tel logit, log, etc, et, encore une fois, où des regroupements d’observations doivent être pris en compte).
Dans les exemples suivants, nous verrons seulement des cas où la variable dépendante est quantitative et normalement distribuée. Nous utiliserons donc la librairie nlme.
Notez que l’estimation des modèles linéaires généralisés mixtes (i.e., les modèles de régression mixtes pour une variable dépendante autre que quantitative normale) présente de nombreuses difficultés :
1) plusieurs des méthodes disponibles sont reconnues pour produire des estimés des coefficients, des erreurs types et des variances qui sont biaisées (Joe, H., 2008)7;
2) des procédures itératives sont utilisées afin de solutionner ces modèles et tout message indiquant un problème de « convergence » de la méthode devraient être pris très au sérieux.
10.2 Évaluer la structure de regroupement
Une première étape primordiale lorsque vous travaillez avec des données structurées est de représenter dans un schéma comme à la figure précédente la structure hypothétique de vos données. Dans ce schéma vous indiquerez aussi à quel niveau se situe chacun de vos prédicteurs et votre variable dépendante (cette dernière sera souvent, mais pas toujours, au niveau le plus bas de la hiérarchie).
Après avoir établi ce schéma, vous pourrez ensuite calculer le nombre moyen d’observations par niveau supérieur et l’étendue du nombre d’observations par niveau supérieur. Vous pourrez ainsi vérifier si certains niveaux sont superflus (e.g., une seule ou peu d’observations par groupe pour ce niveau) ou s’ils pourront être traités autrement que par un effet aléatoire (e.g., groupe inclus comme effet fixe). En fait, vous voudrez établir un tableau similaire au tableau suivant.
| Niveau | Nombre d’unités | Nombre moyen/niveau supérieur | Minimum/niveau supérieur | maximum/niveau supérieur |
| Region | 5 | |||
| Troupeau | 50 | 10 | 3 | 16 |
| Vaches | 1575 | 31.5 | 8 | 105 |
| Lactation | 3027 | 1.9 | 1 | 5 |
Vous pouvez calculer les différents éléments nécessaires pour compléter ce genre de table en utilisant différentes fonctions R de base. Par exemple, pour cette table représentant les données d’une étude où l’unité d’analyse était les lactations, de vaches, de différents troupeaux, dans 5 régions, nous avons utilisé le (long) code R suivant.
#Nous importons le jeu de données
reu_cfs <- read.csv(file="reu_cfs.csv",
header=TRUE,
sep=";"
)
#Nous indiquons les variables catégoriques dans le jeu de données
reu_cfs$region <- factor(reu_cfs$region)
reu_cfs$herd <- factor(reu_cfs$herd)
reu_cfs$cow <- factor(reu_cfs$cow)
reu_cfs$fscr <- factor(reu_cfs$fscr)
reu_cfs$heifer <- factor(reu_cfs$heifer)
reu_cfs$ai <- factor(reu_cfs$ai)
#Nombre total de lactations
dimension <- dim(reu_cfs)
total <- dimension[1]
#Nombre moyen et étendue des lactations par vache
#1) Créer un jeu de données "vaches" où les lactations ont été compilées par vache
library(dplyr)
vaches <- reu_cfs %>%
count(cow)
#Dans ce jeu de données, la variable n représente le nombre de lactations suivies par vache. Nous pouvons donc obtenir la moyenne et l'étendue (minimum et maximum)
dimension <- dim(vaches)
nb_vache <- dimension[1]
mean_lact <- round(mean(vaches$n),
digits=1
)
min_lact <- min(vaches$n)
max_lact <- max(vaches$n)
#2) créer un jeu de données "troupeaux" où les vaches sont regroupées par troupeau. Pour ce faire, on devra procéder en 2 étapes, en regroupant d'abord par troupeau, puis en comptant le nombre de troupeaux:
troupeaux <- reu_cfs %>%
group_by(herd) %>%
count(cow)
troupeaux <- troupeaux %>%
count(herd)
#Dans ce jeu de données, la variable n représente le nombre de vaches par troupeau. Nous pouvons donc obtenir la moyenne et l'étendue (minimum et maximum)
dimension <- dim(troupeaux)
nb_troupeau <- dimension[1]
mean_vache <- round(mean(troupeaux$n),
digits=1
)
min_vache <- min(troupeaux$n)
max_vache <- max(troupeaux$n)
#3) Créer un jeu de données "région" où... (vous aurez compris la suite)
region <- reu_cfs %>%
group_by(region) %>%
count(herd)
region <- region %>%
count(region)
#Dans ce jeu de données, la variable n représente le nombre de troupeaux par région. Nous pouvons donc obtenir la moyenne et l'étendue (minimum et maximum)
dimension <- dim(region)
nb_region <- dimension[1]
mean_troupeau <- round(mean(region$n),
digits=1
)
min_troupeau <- min(region$n)
max_troupeau <- max(region$n)
#Il ne reste plus qu'à assembler toutes ces informations dans une table
ligne_titre <- c("Niveau", "Nombre d'unités", "Nombre moyen/niveau supérieur", "Minimum/niveau supérieur", "maximum/niveau supérieur")
ligne_lact <- c("Lactation", total, mean_lact, min_lact, max_lact)
ligne_vache <- c("Vaches", nb_vache, mean_vache, min_vache, max_vache)
ligne_troupeau <- c("Troupeau", nb_troupeau, mean_troupeau, min_troupeau, max_troupeau)
ligne_region <- c("Region", nb_region, " ", " ", " ")
Structure <- data.frame(rbind(ligne_titre, ligne_region, ligne_troupeau, ligne_vache, ligne_lact))
rownames(Structure) <- NULL
colnames(Structure) <- NULL
library(knitr)
library(kableExtra)
kable(Structure,
caption="Structure des données reu_cfs.csv",
align = "lccc")%>%
kable_styling()10.3 Modèle linéaire mixte
La fonction lme() de la librairie nlme permet d’éxecuter les modèles de régression linéaire mixte (i.e., les modèles de régression où la variable dépendante est quantitative et normalement distribuée et où un ou plusieurs effets aléatoires sont ajoutés). Par exemple, dans l’exemple ci-dessous, un intercept aléatoire (\(\mu_j\)) est ajouté :
\[ Y_{ij} = \beta_0 + \beta_1x_{ij} + \epsilon_{ij} + \mu_j\]
\[ \epsilon_{ij} \sim \text{Normal}(0, \sigma^2)\]
\[ \mu_j \sim \text{Normal}(0, \sigma^2_j) \]
La librairie nlme produira des estimés non-biaisés des coefficients, des erreurs types et des variances. Il n’y a donc pas d’inquiétude à ce sujet. Dans cette section, nous nous concentrerons sur les inférences quant aux coefficients de régression (i.e., les effets fixes) puisque les effets aléatoires sont quant à eux rarement « testés ». Voir la section 21.5.3 de Veterinary Epidemiologic Research (Dohoo et al., 2009) pour plus de détails à ce sujet.
10.4 Modèle mixte avec un seul intercept aléatoire
La syntaxe de la fonction lme() ressemble beaucoup à celle de la fonction lm(). Par exemple, voici le code R pour un modèle où nous voudrions prédire le log du temps entre le vêlage et la saillie fécondante (calving to first service; lncfs) avec un seul prédicteur (heifer) et où il n’y aurait qu’un seul intercept aléatoire (i.e., en considérant seulement que les lactations étaient regroupées par vaches dans le jeu de données reu_cfs.csv). Notez que seule l’argument random= est nouveau. Celui-ci décrit les effets aléatoires. Dans ce cas précis, nous avons indiqué que l’intercept (~ 1) pourra varier en fonction de la vache (| cow)
library(nlme)
model <- lme(data=reu_cfs,
lncfs ~ heifer,
random = ~ 1 | cow)
summary(model)## Linear mixed-effects model fit by REML
## Data: reu_cfs
## AIC BIC logLik
## 3147.071 3171.13 -1569.536
##
## Random effects:
## Formula: ~1 | cow
## (Intercept) Residual
## StdDev: 0.1886308 0.3655125
##
## Fixed effects: lncfs ~ heifer
## Value Std.Error DF t-value p-value
## (Intercept) 4.220263 0.00939379 1574 449.2610 0.0000
## heifer1 -0.017275 0.01751842 1451 -0.9861 0.3242
## Correlation:
## (Intr)
## heifer1 -0.45
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.3970655 -0.6295920 -0.1008050 0.5319296 4.2414756
##
## Number of Observations: 3027
## Number of Groups: 1575Plusieurs des résultats auxquels vous êtes maintenant habitués vous sont présentés. Par exemple, les coefficients des différents paramètres, leur erreur-type et un test de T pour chacun des coefficients. Cependant, on vous rapporte maintenant également le nombre d’observations et le nombre de “groupes” (ici les nombres de lactations et de vaches, respectivement).
10.5 Modèle mixte avec plus d’un intercept aléatoire
Pour ajouter plusieurs intercepts aléatoires, on devra compléter l’argument random = afin de bien indiquer les différents effets aléatoires. À l’aide de barres obliques, on pourra indiquer de quelle manière les groupes sont imbriqués les uns dans les autres. Par exemple, pour inclure les 3 intercepts aléatoires présentés en début de section (i.e., des lactations regroupées par vache, troupeau et région), on écrira random = ~ 1 | region/herd/cow.
library(nlme)
model <- lme(data=reu_cfs,
lncfs ~ heifer,
random = ~ 1 | region/herd/cow)
summary(model)## Linear mixed-effects model fit by REML
## Data: reu_cfs
## AIC BIC logLik
## 3003.739 3039.827 -1495.869
##
## Random effects:
## Formula: ~1 | region
## (Intercept)
## StdDev: 0.01358984
##
## Formula: ~1 | herd %in% region
## (Intercept)
## StdDev: 0.1200085
##
## Formula: ~1 | cow %in% herd %in% region
## (Intercept) Residual
## StdDev: 0.1415776 0.366227
##
## Fixed effects: lncfs ~ heifer
## Value Std.Error DF t-value p-value
## (Intercept) 4.218034 0.02062553 1525 204.50554 0.0000
## heifer1 -0.005917 0.01719443 1451 -0.34412 0.7308
## Correlation:
## (Intr)
## heifer1 -0.192
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.38381984 -0.64661407 -0.09780737 0.56450788 4.52576837
##
## Number of Observations: 3027
## Number of Groups:
## region herd %in% region cow %in% herd %in% region
## 5 50 1575Les résultats présentés sont très similaires. Cependant, on note maintenant que les 3027 lactations étaient bien regroupées parmi 1575 vaches, de 50 troupeaux, dans 5 régions. On note également qu’une structure hierarchique a été précisée (i.e., cow %in% herd %in% region).
10.6 Partition de la variance
L’inclusion d’un ou plusieurs intercept(s) aléatoire(s) permet aussi de s’intéresser à la partition de la variance entre les différents niveaux hiérarchiques. À partir d’un modèle nul (i.e., un modèle sans prédicteurs, mais dans lequel on indique les intercepts aléatoires), on pourra se servir des estimés des variances de chacun des niveaux pour calculer la proportion de la variance qui réside à chacun de ces niveaux. La variation totale est la somme des variances. La proportion de la variation attribuable à un niveau sera la variance de ce niveau divisée par la variance totale.
Les estimés des variances, ne sont pas présentés dans les résultats générés par la fonction summary(). Pour les obtenir, nous devront utiliser la fonction VarCorr() du package nlme.
#Modèle nul (i.e., model sans prédicteurs)
library(nlme)
model <- lme(data=reu_cfs,
lncfs ~ 1,
random = ~ 1 | region/herd/cow)
#Variance
vc <- VarCorr(model)
vc## Variance StdDev
## region = pdLogChol(1)
## (Intercept) 0.0001715063 0.01309604
## herd = pdLogChol(1)
## (Intercept) 0.0144411917 0.12017151
## cow = pdLogChol(1)
## (Intercept) 0.0200263516 0.14151449
## Residual 0.1340883905 0.36618082La variance totale (\(\sigma^2_{totale}\)) serait donc 0.1687 (i.e., 0.1341 + 0.02 + 0.0144 + 0.0002). La proportion de la variation de lncfs attribuable aux caractéristiques des troupeaux serait 8.5% (i.e., \(\frac{\sigma^2_{troupeau}}{ \sigma^2_{totale}}\) ou \(\frac{0.0144}{0.1687}\)).
10.6.1 Coefficient de corrélation intra-classe
La corrélation entre les observations d’un même groupe est décrite par le coefficient de corrélation intraclasse (ICC). L’ICC varie de 0 (indépendance) à 1 (corrélation complète) et s’interprète comme le coefficient \(\rho\) de Pearson. L’ICC se calcule à l’aide des estimés des variances du modèle nul.
Par exemple, la corrélation entre 2 lactations d’une même vache se calculera de la manière suivante :
\[ ICC_{vache} = \frac{\sigma^2_{vache} + \sigma^2_{troupeau} + \sigma^2_{region}}{\sigma^2_{totale}}\]
La corrélation entre 2 lactations d’un même troupeau sera :
\[ ICC_{troupeau} = \frac{\sigma^2_{troupeau} + \sigma^2_{region}}{\sigma^2_{totale}}\]
Entre 2 lactations d’une même région :
\[ ICC_{région} = \frac{\sigma^2_{region}}{\sigma^2_{totale}}\]
Par exemple on aura un \(ICC_{région}\) de 0.001. Donc, il n’y a pratiquement aucune corrélation pour le logarithme naturel du nombre de jours jusqu’à la saillie fécondante (lncfs) entre 2 lactations d’une même région. Cependant, l’\(ICC_{vache}\) était de 0.205 ; il y a donc une certaine corrélation quant au logarithme naturel du nombre de jours jusqu’à la saillie fécondante (lncfs) entre 2 lactations d’une même vache.
10.7 Effet contextuel
Parfois un prédicteur quantitatif peut représenter différents concepts si l’on considère la valeur de l’individu ou la moyenne du groupe. Par exemple, le comptage des cellules somatiques (CCS) en début de lactation a possiblement un effet sur le CCS futur d’une vache puisque le CCS indique une infection et que ces infections vont souvent persister. Le CCS moyen du troupeau en début de lactation à possiblement aussi un effet sur le CCS futur d’une vache, mais parce ce que cela indique la prévalence d’infections (possiblement contagieuses) dans le troupeau et cette prévalence affecte le risque d’acquisition de nouvelles infections par les individus sains.
Pour un prédicteur, la valeur d’un prédicteur pour un individu (effet individuel) et la valeur moyenne du prédicteur pour le groupe (effet contextuel) peuvent être investiguées simplement comme deux prédicteurs différents dans un modèle linéaire mixte. Si les 2 prédicteurs sont testés en même temps dans un même modèle, il faudra penser à centrer le prédicteur au niveau de l’individu (i.e., \(x_{ij} - \tilde{x_{i}}\)) afin d’éviter les problèmes de colinéarité.
Certaines fonctions de base telles group_by() et summarise() du package dplyr pourront vous être utiles afin de créer votre prédicteur au niveau groupe. Par exemple, dans le jeu de données scc_heifer.csv, on s’intéresse à l’effet du CCS en début de lactation (lnsccel, ou “log SCC early lactation) sur le CCS futur de l’animal (lnscc). Une mesure du CCS en début de lactation (sur une échelle logarithmique, lnsccel) a été obtenue pour chacune des 10 996 vaches primipares de 3095 troupeaux. Il s’agit en fait de la valeur centrée (nous n’aurons donc pas à le faire). Afin de créer une variable lnscc.herd représentant le CCS moyen (toujours sur échelle logarithmique) de chacun des troupeaux, nous pourrions utiliser le code suivant.
#Nous importons le jeu de données
scc_heifer <- read.csv(file="scc_heifer.csv",
header=TRUE,
sep=";"
)
#Nous indiquons les variables catégoriques dans le jeu de données
scc_heifer$herd <- factor(scc_heifer$herd)
scc_heifer$cow <- factor(scc_heifer$cow)
#Nous générons un nouveau jeu de données (herddata) qui contiendra le LNSCCEL moyen de chaque troupeau (nous avons nommé cette nouvelle variable HLNSCCELlnscc.herd).
library(dplyr)
herddata <- scc_heifer %>%
group_by(herd) %>%
summarise(lnsccel.herd = mean(lnsccel, na.rm = TRUE))Nous avons maintenant un jeu de données avec les valeurs moyennes pour chacun des 3095 troupeaux. Nous pourrions incorporer ces données dans notre jeu de données original.
scc_heifer2 <- merge(scc_heifer,
herddata,
by="herd"
)Nous pouvons maintenant évaluer un modèle qui contient lnsccel ou lnsccel.herd, ou même les 2 variables en même temps. Par exemple:
library(nlme)
model <- lme(data=scc_heifer2,
lnscc ~ lnsccel + lnsccel.herd,
random = ~ 1 | herd)
summary(model)## Linear mixed-effects model fit by REML
## Data: scc_heifer2
## AIC BIC logLik
## 32639.38 32675.91 -16314.69
##
## Random effects:
## Formula: ~1 | herd
## (Intercept) Residual
## StdDev: 0.3437646 1.018768
##
## Fixed effects: lnscc ~ lnsccel + lnsccel.herd
## Value Std.Error DF t-value p-value
## (Intercept) 4.094196 0.012020252 7900 340.6082 0
## lnsccel 0.241698 0.009480722 7900 25.4936 0
## lnsccel.herd 0.079827 0.018656994 3093 4.2786 0
## Correlation:
## (Intr) lnsccl
## lnsccel 0.000
## lnsccel.herd -0.018 -0.508
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.9446345 -0.6591989 -0.1487921 0.4900957 4.4544510
##
## Number of Observations: 10996
## Number of Groups: 3095Dans ce cas, nous notons qu’être une vache avec un CCS élevé en début de lactation (lnsccel) était associé à une augmentation du CCS futur (+ 0.242 unités par augmentation d’une unité du log CCS de la vache en début de lactation). Être une vache dans un troupeau où le CCS moyen en début de lactation est élevé (lnsccel.herd) était aussi associé au CCS futur de la vache, mais l’effet est moindre (+ 0.08 unités par augmentation d’une unité de du log CCS moyen du troupeau).
10.8 Évaluation du modèle
Les logiciels spécialisés dans les modèles mixtes (e.g., MLwiN) pourront calculer rapidement les résiduels pour chacun des niveaux et produire toutes les figures désirées. Le package nlme n’enregistre que les résiduels du niveau le plus bas. La fonction plot() permet de produire les graphiques permettant d’évaluer l’homoscédasticité des résiduels de ce premier niveau de la hiérarchie. Ceux-ci ont été enregistrés dans notre objet model. Par exemple, pour le modèle prédisant le log du temps entre le vêlage et la saillie fécondante (calving to first service; lncfs) et pour lequel les lactations étaient regroupées par vaches, troupeaux et régions:
library(nlme)
model <- lme(data=reu_cfs,
lncfs ~ heifer,
random = ~ 1 | region/herd/cow)
plot(model,
residuals(.) ~ fitted(.), #Nous demandons la figure des résiduels en y par les valeurs prédites en x
xlab="Valeurs prédites",
ylab="Résiduels"
)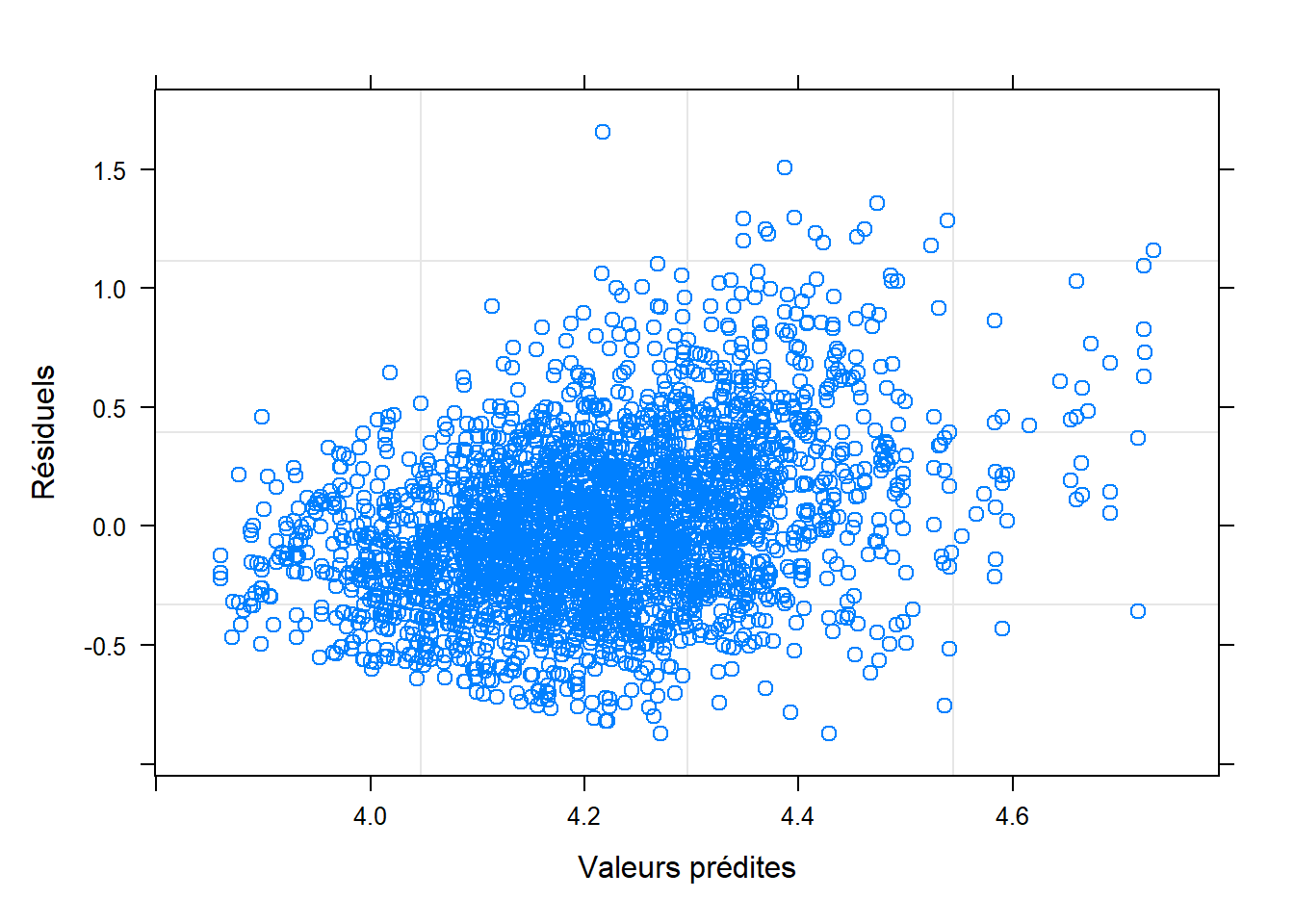
Figure 10.1: Graphique des résiduels x valeurs prédites.
Et la normalité des résiduels du plus bas niveau de la hiérarchie pourrait être évaluée ainsi:
qqnorm(resid(model))
qqline(resid(model))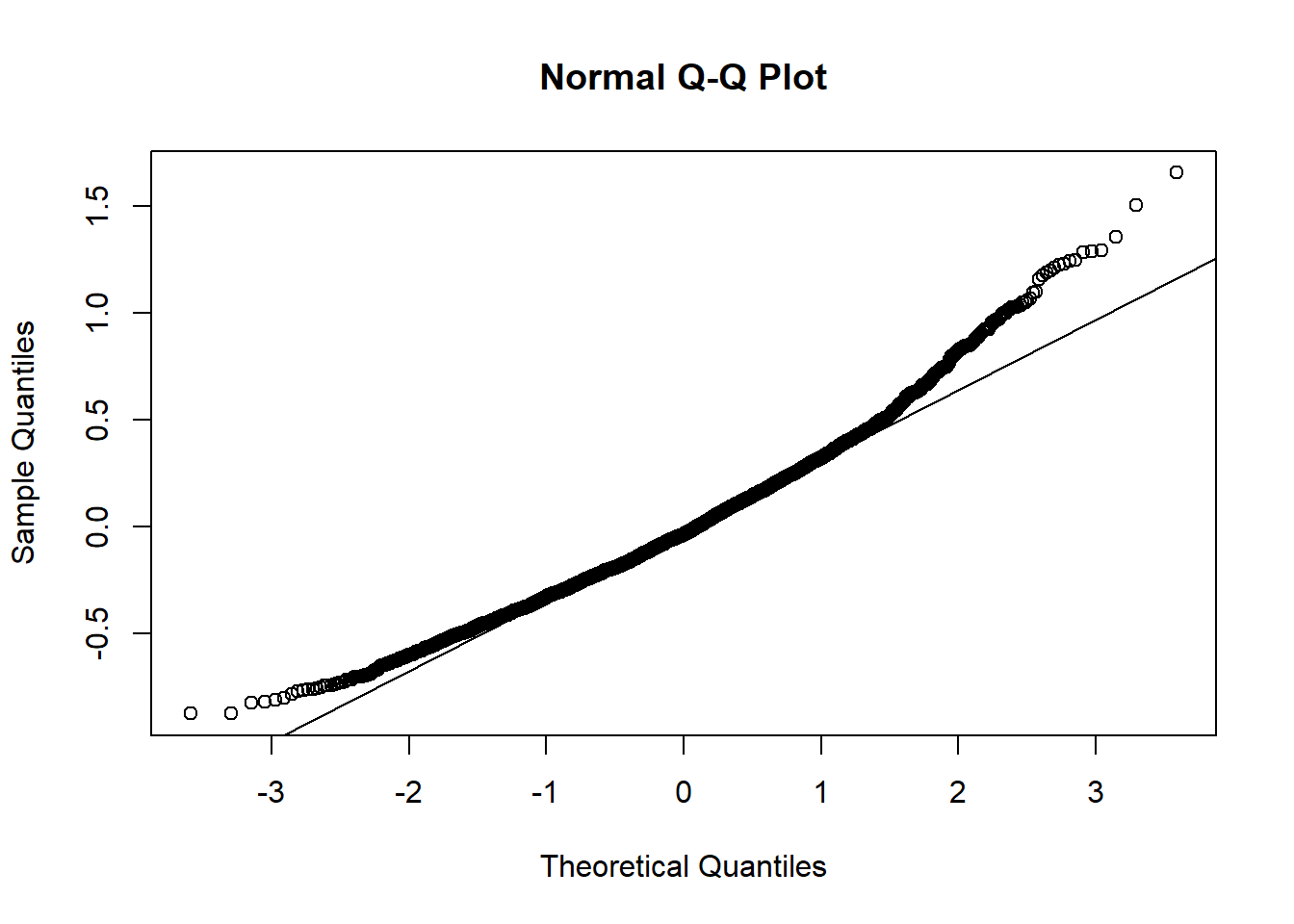
Figure 10.2: Graphique Q-Q des résiduels.
Pour évaluer les résiduels des niveaux supérieurs, nous devrons utiliser la fonction hlm_resid() du package HLMdiag. Par exemple, nous pouvons créer un nouveau jeu de données resid_herd avec les résiduels pour chacun des troupeaux (n=50). Notez que deux types de résiduels sont produits:
- les résiduels
ranef.interceptsont produits en utilisant la méthode “Empirical Bayes estimation”;
- les résiduels
ls.interceptsont produits en utilisant la méthode des moindres carrés.
Ensuite, nous pourrions évaluer la normalité des résiduels avec un graphique Q-Q. Dans l’exemple suivant, nous produirons les résiduels du niveau troupeau.
library(HLMdiag)
resid_herd <- hlm_resid(model,
level="herd"
)
qqnorm(resid_herd$.ranef.intercept)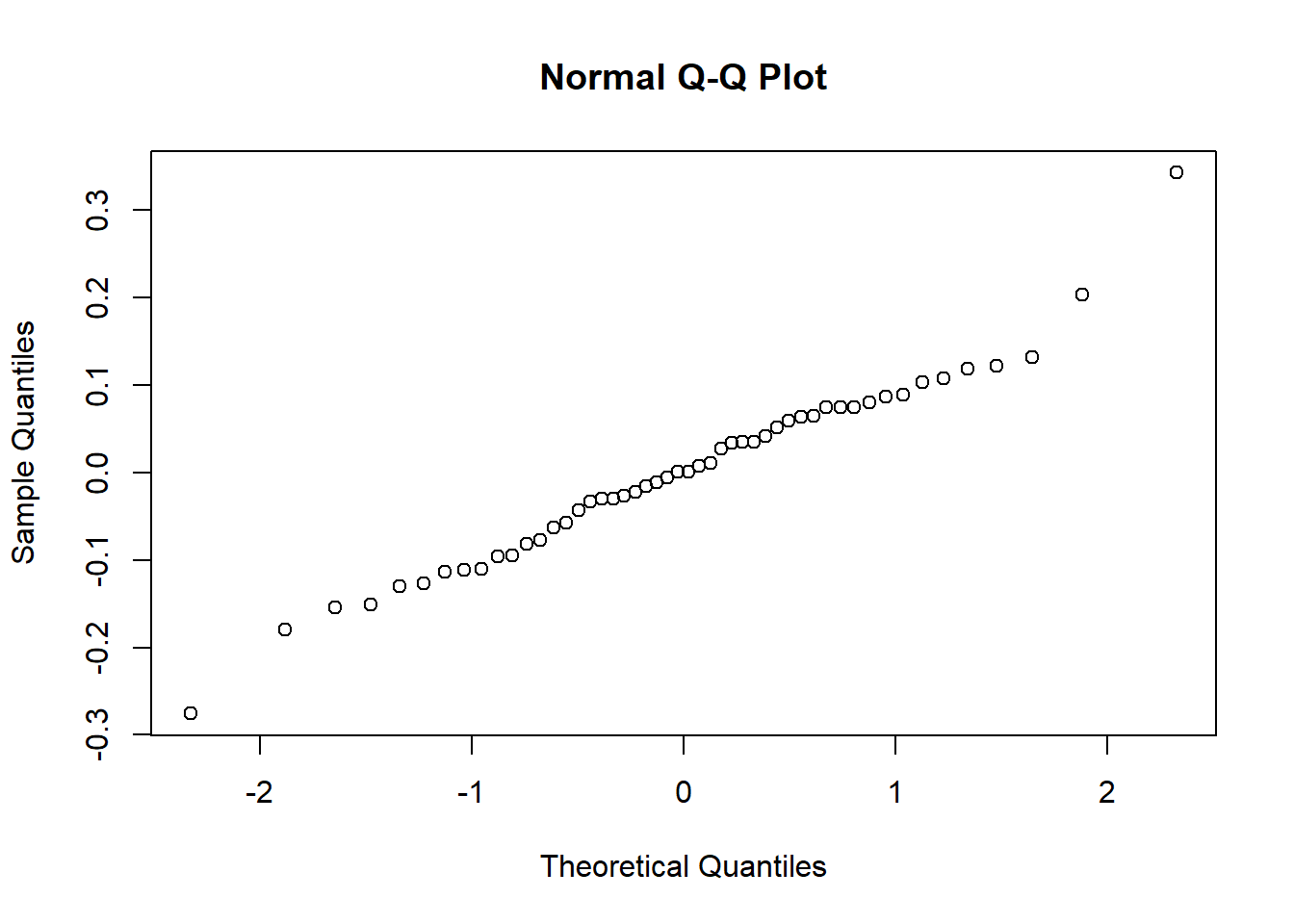
Figure 10.3: Graphique Q-Q des résiduels du niveau troupeau.
Il faudrait ensuite répéter cette évaluation pour les résiduels du niveau vache, et ceux du niveau région. Notez que la fonction hlm_resid() ne produit pas les valeurs prédites par le modèle. Ce n’est donc pas possible de vérifier l’homoscédasticité des résiduels des niveaux supérieurs (i.e., de produire une figure des résiduels x valeurs prédites).
Finalement, vous pourriez aussi produire un nouveau jeu de données contenant les distances de Cook, les leviers et les différentes mesures vous permettant d’évaluer votre modèle en utilisant la fonction hlm_influence(). Notez que, si le jeu de données est large et que plusieurs intercepts aléatoires sont utilisés (comme ici), cette fonction peut prendre plusieurs minutes avant de produire le jeu de données demandé. Dans l’exemple suivant, nous produirons les mesures d’influence pour le niveau le plus bas de la hiéarchie en indiquant level=1. Nous aurions pu remplacer par level="cow", level="herd" ou level="region" pour évaluer, respectivement, les vaches, troupeaux et régions les plus influents.
library(HLMdiag)
infl_lact <- hlm_influence(model,
level=1
)10.9 Pentes aléatoires
Avec le modèle avec un ou plusieurs intercepts aléatoires, les groupes diffèrent entre eux pour la valeur moyenne de la variable dépendante : le seul effet aléatoire est un intercept aléatoire. Mais il se peut que l’effet d’un prédicteur quantitatif soit différent dans un groupe plutôt qu’un autre (i.e., la pente diffère entre les groupes). Les jours en lait, par exemple, pourraient avoir un effet plus important sur le comptage en cellules somatiques dans certains troupeaux que dans d’autres. Il y aurait alors une hétérogénéité des pentes des droites de régression selon le troupeau. On peut le modéliser grâce à une pente aléatoire.
Par exemple, dans le jeu de données scc40_2level.csv, le CCS (lnscc, donc sur une échelle logarithmique) de 2178 vaches de 40 troupeaux a été mesuré (une seule mesure par vache). Les observations dans ce jeu de données sont donc regroupées par troupeau. Un modèle avec seulement un intercept aléatoire (i.e., un modèle hiérarchique à 2 niveaux) pourrait être évalué comme suit :
\[ TLNSCC_{ij} = \beta_0 + \beta_1TDIM_{ij} + \epsilon_{ij} + \mu_j\] \[ \epsilon_{ij} \sim \text{Normal}(0, \sigma^2)\] \[ \mu_j \sim \text{Normal}(0, \sigma^2_j) \]
Où \(TLNSCC_{ij}\) est le logarithme naturel du comptage des cellules somatiques (log CCS) de la vache i du troupeau j ; \(\beta_0\) est le log CCS moyen ; \(\beta_1\) est l’effet des jours en lait sur le log CCS ; \(TDIM_{ij}\) est le nombre de jours en lait au moment du test de la vache i du troupeau j ; \(\epsilon_{ij}\) est le résiduel pour la vache i du troupeau j ; et \(mu_j\) est la variation autour de l’effet moyen attribuable au troupeau j. Ce modèle s’écrirait comme suit :
#Nous importons le jeu de données
scc40 <- read.csv(file="scc40_2level.csv",
header=TRUE,
sep=";"
)
#Nous indiquons les variables catégoriques dans le jeu de données
scc40$herdid <- factor(scc40$herdid)
scc40$cowid <- factor(scc40$cowid)
scc40$c_heifer <- factor(scc40$c_heifer)
scc40$t_season <- factor(scc40$t_season)
#Le modèle avec intercept aléatoire
library(nlme)
model <- lme(data=scc40,
t_lnscc ~ t_dim,
random = ~ 1 | herdid)
summary(model)## Linear mixed-effects model fit by REML
## Data: scc40
## AIC BIC logLik
## 7418.019 7440.76 -3705.009
##
## Random effects:
## Formula: ~1 | herdid
## (Intercept) Residual
## StdDev: 0.3797328 1.301221
##
## Fixed effects: t_lnscc ~ t_dim
## Value Std.Error DF t-value p-value
## (Intercept) 4.553489 0.07253184 2137 62.77917 0
## t_dim 0.003201 0.00045701 2137 7.00493 0
## Correlation:
## (Intr)
## t_dim -0.38
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.5011087 -0.7408145 -0.1206297 0.6477404 3.1693563
##
## Number of Observations: 2178
## Number of Groups: 40Dans ce modèle on suppose donc que l’effet de t_dim (i.e., \(\beta_1\)) est le même dans tous les troupeaux, seul l’intercept (représenté par le symbole 1 dans random = ~ 1 | herdid) change en fonction du troupeau comme illustré à la figure suivante. Dans cette figure, chaque ligne représente la droite de régression d’un des 40 troupeaux. On voit que le log CCS augmente toujours de la même manière avec les jours en lait, mais que le log CCS moyen (i.e., l’intercept) varie en fonction du troupeau.
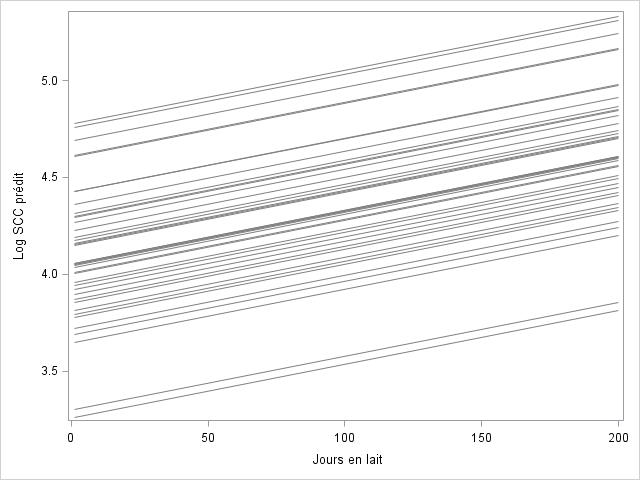
Représentation schématique d’un modèle mixte avec intercept aléatoire.
Si cela semble plus logique de permettre que l’effet d’un prédicteur varie en fonction du groupe, on pourra alors ajouter une pente aléatoire (\(\beta_j\)) pour ce prédicteur, comme suit.
\[ TLNSCC_{ij} = \beta_0 + \beta_1TDIM_{ij} + \epsilon_{ij} + \beta_jTDIM_{ij} + \mu_j\] \[ \epsilon_{ij} \sim \text{Normal}(0, \sigma^2)\] \[ \mu_j \sim \text{Normal}(0, \sigma^2_j) \] \[ \beta_j \sim \text{Normal}(0, \sigma^2_l) \]
Où \(\beta_j\) est la variation de la pente de t_dim en fonction du troupeau. Le paramètre \(\sigma^2_l\) est alors la variance de la pente de t_dim entre les troupeaux. Ce modèle s’écrit comme suit :
#Le modèle avec intercept et pente t_dim aléatoire
library(nlme)
model <- lme(data=scc40,
t_lnscc ~ t_dim,
random = ~ 1 + t_dim | herdid)
summary(model)## Linear mixed-effects model fit by REML
## Data: scc40
## AIC BIC logLik
## 7417.854 7451.965 -3702.927
##
## Random effects:
## Formula: ~1 + t_dim | herdid
## Structure: General positive-definite, Log-Cholesky parametrization
## StdDev Corr
## (Intercept) 0.435627406 (Intr)
## t_dim 0.001970772 -0.54
## Residual 1.295588142
##
## Fixed effects: t_lnscc ~ t_dim
## Value Std.Error DF t-value p-value
## (Intercept) 4.556627 0.08022597 2137 56.79741 0
## t_dim 0.003188 0.00056379 2137 5.65515 0
## Correlation:
## (Intr)
## t_dim -0.55
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.3960515 -0.7406232 -0.1138172 0.6484076 3.2099487
##
## Number of Observations: 2178
## Number of Groups: 40Dans ce modèle on suppose donc que, non seulement l’intercept (le 1 dans random = ~ 1 + t_dim | herdid), mais aussi l’effet de t_dim (i.e., \(\beta_1\) ou la pente de t_dim) diffèrent en fonction du troupeau. Pourtant, vous noterez que vous obtenez tout de même une seule valeur, 0.003, pour le coefficient de t_dim. Il s’agit de la pente moyenne.
Dans le modèle avec intercept et pente aléatoire, l’intercept ET la pente (\(\beta_1\)) changent donc en fonction du troupeau comme illustré à la figure suivante où l’on voit que le log CCS moyen est différent ET qu’il ne change pas toujours de la même manière avec les jours en lait, en fonction du troupeau.

Représentation schématique d’un modèle mixte avec intercept et pente aléatoires.
10.10 Travaux pratiques 10 - Modèles linéaires mixtes
10.10.1 Exercices
Pour ce TP utilisez le fichier SCC40_2level.csv (voir description VER p.832).
Ce jeu de données provient d’une étude observationnelle dont le but était d’évaluer l’effet de différentes caractéristiques des vaches (âge [c_heifer], taille du troupeau [h_size], saison [t_season], jours en lait [t_dim], mois de la lactation [test]) sur le CCS des vaches (t_lnscc, sur une base logarithmique). Une seule observation est disponible sur chacune des 2178 vaches de 40 troupeaux.
Représentez schématiquement la structure de ces données, indiquez à quel niveau chacun des prédicteurs se situe et le nombre moyen, minimum et maximum d’observations par groupe.
Quelle proportion de la variation du logarithme naturel du comptage des cellules somatiques (t_lnscc) peut être expliquée par les caractéristiques des vaches vs. des troupeaux ?
Quelle est la corrélation entre 2 vaches d’un même troupeau quant à leur mesure de log CCS ? Comment interprétez-vous cette mesure ?
Question boni (valide pour 10 banana-points). Dans ce cas-ci, quel est l’effet du dessin d’étude sur la variance (i.e., elle augmente ou diminue et de combien) ?
Quel est l’effet des jours en lait (t_dim) sur le log CCS (supposez que t_dim a une relation linéaire avec t_lnscc) ?
Vous vous demandez si le fait d’être dans un troupeau de vaches « avancées » en lactation pourrait aussi avoir un effet sur le CCS individuel. En général, la prévalence d’infections est plus élevée chez les vaches en fin de lactation et une prévalence d’infection élevée dans un troupeau augmente, en théorie, le risque qu’une vache individuelle ait un CCS élevé.
6.1. Comment nomme-t’on ce genre d’effet ?
6.2. Dans ce cas-ci quel est l’effet d’être dans un troupeau avec un nombre moyen de jours en lait élevé vs. d’être une vache avec un nombre de jours en lait élevé ?
- Que pensez-vous des suppositions des résiduels (au niveau le plus bas) pour le modèle avec t_dim seulement ?
10.10.2 Code R et réponses
Pour ce TP utilisez le fichier SCC40_2level.csv (voir description VER p.832).
#Nous importons le jeu de données
scc40 <- read.csv(file="scc40_2level.csv",
header=TRUE,
sep=";"
)
#Nous indiquons les variables catégoriques dans le jeu de données
scc40$herdid <- factor(scc40$herdid)
scc40$cowid <- factor(scc40$cowid)
scc40$c_heifer <- factor(scc40$c_heifer)
scc40$t_season <- factor(scc40$t_season)Ce jeu de données provient d’une étude observationnelle dont le but était d’évaluer l’effet de différentes caractéristiques des vaches (âge [c_heifer], taille du troupeau [h_size], saison [t_season], jours en lait [t_dim], mois de la lactation [test]) sur le CCS des vaches (t_lnscc, sur une base logarithmique). Une seule observation est disponible sur chacune des 2178 vaches de 40 troupeaux.
- Représentez schématiquement la structure de ces données, indiquez à quel niveau chacun des prédicteurs se situe et le nombre moyen, minimum et maximum d’observations par groupe.
Réponse: Il y a simplement 2 niveaux, un niveau vache imbriqué dans un niveau troupeau. Les variables t_lnscc (la variable dépendante) et les variables test, c_heifer, t_season et t_dim sont au niveau vache, la variable h_size est une variable de niveau troupeau.
#Nombre total de vachess
dimension <- dim(scc40)
total <- dimension[1]
#Nombre moyen et étendue des vaches par troupeau
#Créer un jeu de données "troupeau" où les vachess ont été compilées par troupeau
library(dplyr)
troupeau <- scc40 %>%
count(herdid)
#Dans ce jeu de données, la variable n représente le nombre de vaches suivies par troupeau. Nous pouvons donc obtenir la moyenne et l'étendue (minimum et maximum)
dimension <- dim(troupeau)
nb_troupeau <- dimension[1]
mean_vache <- round(mean(troupeau$n),
digits=1
)
min_vache <- min(troupeau$n)
max_vache <- max(troupeau$n)
#Il ne reste plus qu'à assembler toutes ces informations dans une table
ligne_titre <- c("Niveau", "Nombre d'unités", "Nombre moyen/niveau supérieur", "Minimum/niveau supérieur", "maximum/niveau supérieur")
ligne_vache <- c("Vaches", total, mean_vache, min_vache, max_vache)
ligne_troupeau <- c("Troupeau", nb_troupeau, " ", " ", " ")
Structure <- data.frame(rbind(ligne_titre,
ligne_troupeau,
ligne_vache)
)
rownames(Structure) <- NULL
colnames(Structure) <- NULL
library(knitr)
library(kableExtra)
kable(Structure,
caption="Structure des données scc40_2level.csv",
align = "lccc")%>%
kable_styling()| Niveau | Nombre d’unités | Nombre moyen/niveau supérieur | Minimum/niveau supérieur | maximum/niveau supérieur |
| Troupeau | 40 | |||
| Vaches | 2178 | 54.5 | 12 | 105 |
- Quelle proportion de la variation du logarithme naturel du comptage des cellules somatiques (t_lnscc) peut être expliquée par les caractéristiques des vaches vs. des troupeaux ?
#Avec un modèle sans aucun prédicteurs, nous pourrons obtenir les variances vache et troupeau
library(nlme)
model <- lme(data=scc40,
t_lnscc ~ 1 ,
random = ~ 1 | herdid)
vc <- VarCorr(model)
vc## herdid = pdLogChol(1)
## Variance StdDev
## (Intercept) 0.1482565 0.3850409
## Residual 1.7304132 1.3154517#Nous pourrions calculer directement dans R
options(scipen=999) #Cet argument nous permet d'éviter la notation scientifique
var.herd <- round(as.numeric(vc[1, 1:1]),
digits=4)
var.cow <- round(as.numeric(vc[2, 1:1]),
digits=4)
var.tot <- var.herd + var.cow
prop.herd <- round(var.herd/var.tot*100,
digits=1
)
prop.cow <- round(var.cow/var.tot*100,
digits=1
)Réponse: La variance au niveau vache était 1.7304, celle au niveau troupeau était 0.1483 et la variance totale est donc 1.8787. Les caractéristiques des vaches (e.g., âge, statut infectieux, jours en lait, génétique) expliquent 92.1% de la variation du log CCS, alors que les caractéristiques des troupeaux (e.g., logement, alimentation, éleveur) expliquent 7.9% de la variation du log CCS.
- Quelle est la corrélation entre 2 vaches d’un même troupeau quant à leur mesure de log CCS ? Comment interprétez-vous cette mesure ?
#Encore une fois, nous pourrions effectuer le calcul à l'aide de R
icc.vache <- round((var.herd)/var.tot,
digits=3)
icc.vache## [1] 0.079Réponse: L’\(ICC_{troupeau}\) était de 0.079. Il y a une certaine corrélation entre les mesures de log CCS de vaches de même troupeau (i.e., les vaches ont tendance à avoir des log CCS similaires lorsqu’elles viennent d’un même troupeau), mais cette corrélation est tout de même faible.
- Question boni (valide pour 10 banana-points). Dans ce cas-ci, quel est l’effet du dessin d’étude sur la variance (i.e., elle augmente ou diminue et de combien) ?
Réponse: Nous pourrions calculer le “design effect”.
\[deff = (1+(m-1)*\rho)\]
\[deff = (1+(54.5-1)*0.079) = 5.23\]
La variance est 5.23 fois plus grande à cause de l’agrégation des observations qu’elle ne le serait si les observations étaient indépendantes.
- Quel est l’effet des jours en lait (t_dim) sur le log CCS (supposez que t_dim a une relation linéaire avec t_lnscc) ?
library(nlme)
model <- lme(data=scc40,
t_lnscc ~ t_dim ,
random = ~ 1 | herdid)
summary(model)## Linear mixed-effects model fit by REML
## Data: scc40
## AIC BIC logLik
## 7418.019 7440.76 -3705.009
##
## Random effects:
## Formula: ~1 | herdid
## (Intercept) Residual
## StdDev: 0.3797328 1.301221
##
## Fixed effects: t_lnscc ~ t_dim
## Value Std.Error DF t-value p-value
## (Intercept) 4.553489 0.07253184 2137 62.77917 0
## t_dim 0.003201 0.00045701 2137 7.00493 0
## Correlation:
## (Intr)
## t_dim -0.38
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.5011087 -0.7408145 -0.1206297 0.6477404 3.1693563
##
## Number of Observations: 2178
## Number of Groups: 40Réponse: Le log CCS augmente de 0.003 lorsque jours en lait augmente de 1.
- Vous vous demandez si le fait d’être dans un troupeau de vaches « avancées » en lactation pourrait aussi avoir un effet sur le CCS individuel. En général, la prévalence d’infections est plus élevée chez les vaches en fin de lactation et une prévalence d’infection élevée dans un troupeau augmente, en théorie, le risque qu’une vache individuelle ait un CCS élevé.
6.1. Comment nomme-t’on ce genre d’effet ?
Réponse: Un effet contextuel.
6.2. Dans ce cas-ci quel est l’effet d’être dans un troupeau avec un nombre moyen de jours en lait élevé vs. d’être une vache avec un nombre de jours en lait élevé ?
#Centrons la variable t_dim sur sa moyenne
scc40$t_dim_ct <- scc40$t_dim - mean(scc40$t_dim)
#Nous générons un nouveau jeu de données (herddata) qui contiendra le t_dim moyen de chaque troupeau (nous avons nommé cette nouvelle variable t_dim.herd).
library(dplyr)
herddata <- scc40 %>%
group_by(herdid) %>%
summarise(t_dim.herd = mean(t_dim_ct, na.rm = TRUE))
#Réunir ces valeurs dans le jeu de données original
scc40_2 <- merge(scc40,
herddata,
by="herdid"
)
#Modéliser l'effet d'être dans un troupeau avec un nombre de jours en lait moyen élevé
library(nlme)
model <- lme(data=scc40_2,
t_lnscc ~ t_dim_ct + t_dim.herd,
random = ~ 1 | herdid)
summary(model)## Linear mixed-effects model fit by REML
## Data: scc40_2
## AIC BIC logLik
## 7427.906 7456.33 -3708.953
##
## Random effects:
## Formula: ~1 | herdid
## (Intercept) Residual
## StdDev: 0.3825484 1.301231
##
## Fixed effects: t_lnscc ~ t_dim_ct + t_dim.herd
## Value Std.Error DF t-value p-value
## (Intercept) 4.746819 0.06748365 2137 70.34028 0.0000
## t_dim_ct 0.003176 0.00045836 2137 6.92917 0.0000
## t_dim.herd 0.004280 0.00600544 38 0.71262 0.4804
## Correlation:
## (Intr) t_dm_c
## t_dim_ct 0.000
## t_dim.herd 0.001 -0.076
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -2.4970293 -0.7399995 -0.1191294 0.6517849 3.1790416
##
## Number of Observations: 2178
## Number of Groups: 40Réponse: Lorsque le nombre de jours en lait moyen du troupeau augmente de 1, le log CCS de la vache augmente de 0.004. Au niveau individuel, lorsque le nombre de jours en lait d’une vache augmente de 1, son log CCS augmente de 0.003. Dans ce cas, l’effet contextuel n’est pas significatif, ce ne serait donc pas nécessaire de le conserver dans le modèle. L’effet individuel, cependant est significatif.
- Que pensez-vous des suppositions des résiduels (au niveau le plus bas) pour le modèle avec t_dim seulement ?
library(nlme)
model <- lme(data=scc40,
t_lnscc ~ t_dim ,
random = ~ 1 | herdid)
plot(model,
residuals(.) ~ fitted(.), #Nous demandons la figure des résiduels en y par les valeurs prédites en x
xlab="Valeurs prédites",
ylab="Résiduels"
)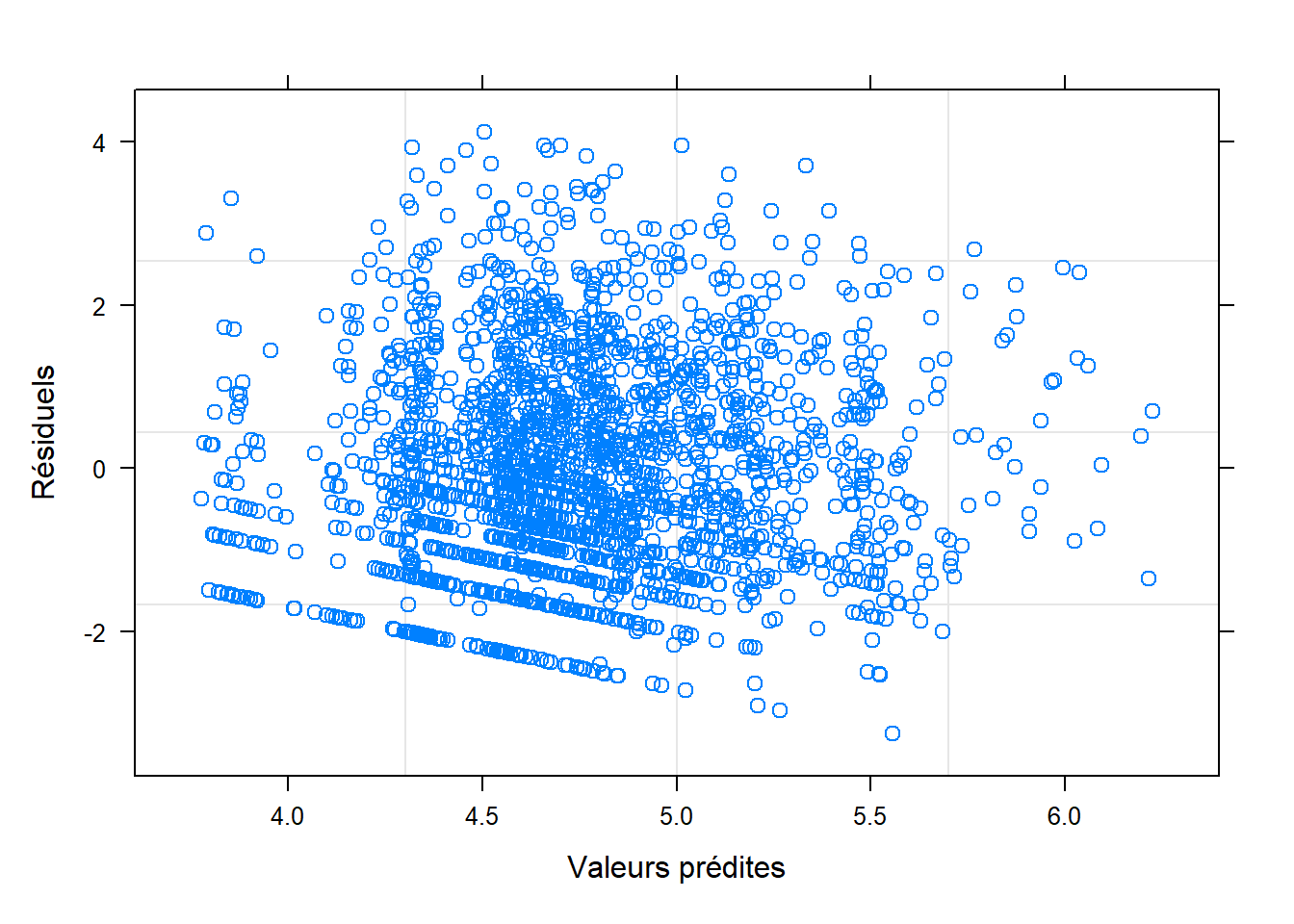
Figure 10.4: Graphique des résiduels x valeurs prédites.
qqnorm(resid(model))
qqline(resid(model))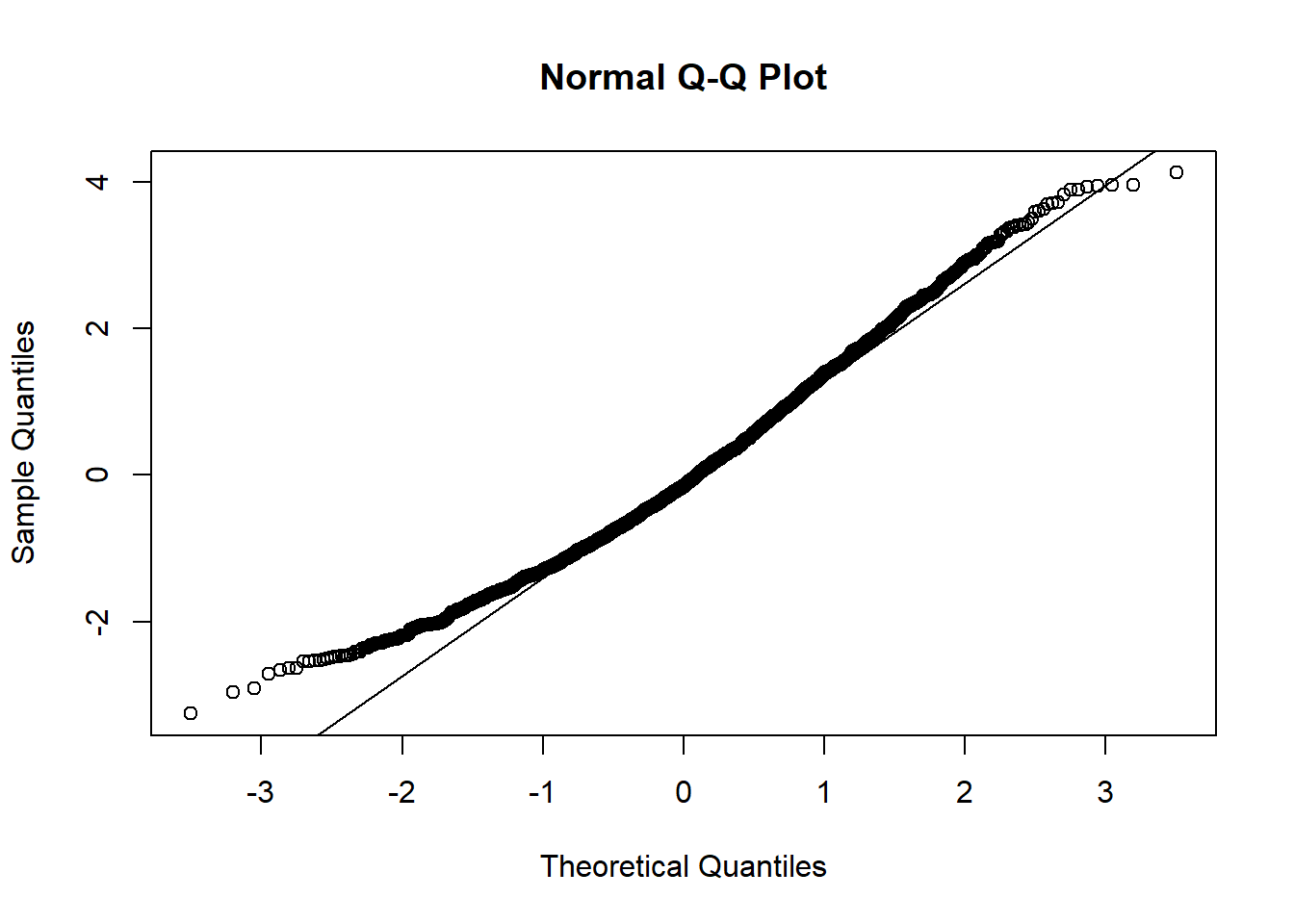
Figure 10.5: Graphique Q-Q des résiduels.
Réponse: Normalité et homoscédasticité des résiduels semblent respectées (i.e., pas vraiment d’augmentation de la variance des résiduels en fonction des valeurs prédites).