Chapitre 6 Régression linéaire
6.1 Généralités
La fonction de base dans R pour la régression linéaire est la fonction lm(). Pour les exemples suivants, nous allons utiliser que les troupeaux du jeu de données Daisy2.xlsx avec h7=1.
daisy2 <- read.csv(file="daisy2.csv",
header=TRUE,
sep=",")
daisy2_mod <- subset(daisy2,
h7==1)Une régression linéaire dans sa plus simple expression pourrait être:
modele <- lm(data=daisy2_mod,
milk120 ~ (parity+twin)
) #Nous avons créé un nouvel objet qui s'appelle modele et qui est une régression des variables parity et twin sur milk120
modele #Nous demandons à voir l'objet modele##
## Call:
## lm(formula = milk120 ~ (parity + twin), data = daisy2_mod)
##
## Coefficients:
## (Intercept) parity twin
## 2734.9 172.5 -150.6Les résultats présentés sont simplement l’intercept et les coefficients de parity et de twin. Pour une vache avec parity=0 et twin=0 le modèle prédit 2734,9kg de lait en 120 jours. On ajoute 172,5kg pour chaque augmentation de 1 unité de parity et on enlève 150,6kg lorsque twin est présent. Si vous préférez:
\[ milk120 = 2734,9 + 172,5*parity - 150,6*twin \]
Pour avoir un peu plus d’informations sur ce modèle, vous pouvez demander:
summary(modele) #Nous demandons un résumé de l'objet modele##
## Call:
## lm(formula = milk120 ~ (parity + twin), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1969.69 -434.13 -7.12 422.23 2147.50
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2734.865 32.313 84.64 <2e-16 ***
## parity 172.513 9.923 17.39 <2e-16 ***
## twin -150.557 101.741 -1.48 0.139
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 650.3 on 1765 degrees of freedom
## (208 observations effacées parce que manquantes)
## Multiple R-squared: 0.1463, Adjusted R-squared: 0.1453
## F-statistic: 151.2 on 2 and 1765 DF, p-value: < 2.2e-16Quelques infos sont alors présentées sur:
- Les résiduels (par exemple, le min et le max).
- Votre modèle, mais cette fois avec les erreurs-types de chacun des coefficients et les valeurs de P pour le test de T de chaque coefficient.
- L’erreur-type des résiduels est également rapportée (650.3) de même que les degrés de liberté (1765) et le nombre d’observations manquantes (208).
- Le \(R^2\) (le coefficient de détermination) est présenté. Dans ce cas 14.63% de la variation de milk120 est expliquée par le modèle.
- La valeur de F (151.2) qui teste si tous les coefficients=0 est aussi rapportée, de même que ses degrés de libertés (2 et 1765) et la valeur de P associée (P<0.01).
Vous pouvez demander à voir la table ANOVA à l’aide de la fonction aov().
aov<-aov(modele) #Nous créons un objet aov
summary(aov) #Nous demandons de résumer cet objet aov## Df Sum Sq Mean Sq F value Pr(>F)
## parity 1 126939726 126939726 300.21 <2e-16 ***
## twin 1 925932 925932 2.19 0.139
## Residuals 1765 746306281 422836
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## 208 observations effacées parce que manquantesFinalement, notez que parity a été traitée comme une variable quantitative. Si vous désirez qu’elle soit traitée comme une variable catégorique, vous pourriez soit créer une nouvelle variable catégorique et l’utiliser dans le modèle.
daisy2_mod$par_cat <- factor(daisy2_mod$parity)Soit l’écrire directement dans le modèle.
modele1 <- lm(data=daisy2_mod,
milk120 ~ (factor(parity)+twin)
) #Factor() nous permet d'indiquer qu'une variable est catégorique
modele1 ##
## Call:
## lm(formula = milk120 ~ (factor(parity) + twin), data = daisy2_mod)
##
## Coefficients:
## (Intercept) factor(parity)2 factor(parity)3 factor(parity)4
## 2630.9 719.3 798.9 836.2
## factor(parity)5 factor(parity)6 factor(parity)7 twin
## 818.8 937.6 793.9 -192.3Il y aura maintenant un coefficient pour chaque niveau de la variable parity sauf le niveau de référence (parity=1 a été choisi comme référence ici).
6.2 Ajouter des intervalles de confiance
Des IC95% pour chacun des paramètres estimés seront obtenus comme suit à l’aide de la fonction confint():
confint(modele,
level= 0.95)## 2.5 % 97.5 %
## (Intercept) 2671.4897 2798.2413
## parity 153.0500 191.9752
## twin -350.1027 48.98926.3 Test de F pour comparer modèles complet vs. réduit
Tester si quelques coefficients spécifiques sont différents de zéro (i.e., comparer un modèle complet et un modèle réduit) est très simple dans R. Il faut d’abord faire rouler chaque modèle. Par exemple, dans le modèle suivant, pour tester les 4 problèmes de reproduction (twin, dyst, rp et vag_disch) ensemble, vous devrez exécuter les 2 modèles suivants
modele_complet <- lm(data=daisy2_mod,
milk120 ~ (parity+twin+dyst+rp+vag_disch)
)
modele_reduit <- lm(data=daisy2_mod,
milk120 ~ (parity)
)Ensuite, on peut utiliser la fonction anova() pour comparer les modèles.
anova(modele_complet, modele_reduit)## Analysis of Variance Table
##
## Model 1: milk120 ~ (parity + twin + dyst + rp + vag_disch)
## Model 2: milk120 ~ (parity)
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 1762 744046844
## 2 1766 747232213 -4 -3185369 1.8858 0.1103Dans ce cas, on obtient une valeur de P de 0.11. Donc, le modèle complet n’est pas meilleur ou, si vous préférez, les coefficients de twin, dyst, rp et vag_disch ne sont pas différents de zéro.
6.4 Transformer une variable
Pour transformer une variable (e.g. centrer, mettre à l’échelle, mettre au carré ou au cube), vous pouvez simplement utiliser les notions de base pour créer une nouvelle variable dans votre jeu de données. Vous pourrez ensuite utiliser cette nouvelle variable dans votre modèle. Par exemple, le code suivant permet de créer 3 nouvelles variables.
daisy2_mod$parity_ct <- daisy2_mod$parity-1
daisy2_mod$herd_size_ct_sc <- (daisy2_mod$herd_size-250)/100
daisy2_mod$herd_size_sq <- daisy2_mod$herd_size_ct_sc*daisy2_mod$herd_size_ct_sc- Une variable parity centrée sur la valeur 1 (i.e., le 1 devient le zéro pour cette nouvelle variable);
- Une nouvelle variable herd_size_ct_sc centrée sur 250 vaches et mise à l’échelle pour représenter une augmentation de 100 vaches;
- Une nouvelle variable herd_size_sq qui est la variable herd_size centrée, mise à l’échelle et élevé au carré (i.e. un terme polynomial qui pourra être utilisé afin de vérifier la linéarité de la relation entre herd_size et votre variable dépendante).
6.5 Choisir la valeur de référence pour une variable catégorique
Notez que pour les variables catégoriques, R décide (et pas toujours bien) de la valeur de référence. On peut tout de même forcer la valeur de référence qui nous intéresse. Dans le code suivant, j’ai indiqué en utilisant la fonction relevel() que, pour la variable par_cat créée précédemment, la valeur 2 sera la catégorie de référence. Lorsque j’utilise ensuite cette variable dans un modèle statistique, la valeur 2 est automatiquement utilisée comme référence.
daisy2_mod <- within(daisy2_mod,
par_cat <- relevel(par_cat, ref=2)
) #Sélection de la valeur de référence par_cat=2
modele2 <- lm(data=daisy2_mod,
milk120 ~ (par_cat+twin)
)
summary(modele2)##
## Call:
## lm(formula = milk120 ~ (par_cat + twin), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2240.03 -382.80 3.92 373.68 2180.58
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3350.23 30.80 108.777 < 2e-16 ***
## par_cat1 -719.28 42.46 -16.938 < 2e-16 ***
## par_cat3 79.60 44.96 1.771 0.07681 .
## par_cat4 116.96 49.33 2.371 0.01785 *
## par_cat5 99.49 51.56 1.930 0.05382 .
## par_cat6 218.27 67.51 3.233 0.00125 **
## par_cat7 74.66 218.88 0.341 0.73308
## twin -192.25 96.06 -2.001 0.04550 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 612.9 on 1760 degrees of freedom
## (208 observations effacées parce que manquantes)
## Multiple R-squared: 0.2436, Adjusted R-squared: 0.2406
## F-statistic: 80.98 on 7 and 1760 DF, p-value: < 2.2e-166.6 Comparer les niveaux d’un prédicteur catégorique avec >2 catégories
Pour un prédicteur catégorique avec plus de 2 catégories, on voudra d’abord savoir si le prédicteur est significativement associé à la variable dépendante (i.e. test de F). Si c’est le cas, on voudra alors comparer les niveaux entre eux (i.e. tests de T). Deux problèmes se posent alors :
1) Problème de comparaisons multiples; on voudra ajuster nos valeurs de P ou nos IC 95% en fonction du nombre de comparaisons effectuées.
2) La table avec les coefficients de régression nous rapporte le test de T pour chaque coefficient, lorsque comparé au niveau de référence, mais pas entre eux.
Par exemple, avec une variable parity_cat avec 3 catégories : 1=parité 1, 2=parité 2 et 3=parité ≥ 3, on aura
#Nous créons une variable parity catégorique:
daisy2_mod$par_cat <- cut(daisy2_mod$parity,
breaks = c(0, 1, 2, Inf),
labels = c("First", "Second", "Third or more")
)
#La régression
modele <- lm(data=daisy2_mod,
milk120 ~ (par_cat)
)
summary(modele)##
## Call:
## lm(formula = milk120 ~ (par_cat), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2234.73 -387.55 7.79 377.11 2176.01
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2629.63 29.31 89.71 <2e-16 ***
## par_catSecond 715.30 42.45 16.85 <2e-16 ***
## par_catThird or more 824.66 35.54 23.20 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 613.5 on 1765 degrees of freedom
## (208 observations effacées parce que manquantes)
## Multiple R-squared: 0.2402, Adjusted R-squared: 0.2393
## F-statistic: 278.9 on 2 and 1765 DF, p-value: < 2.2e-16Dans les résultats, les tests de T nous indiquent que Second est différent de First (la catégorie de référence) et que Third or more est différent de First. Mais on ne peut comparer Second avec Third or more et ces valeurs de T ne sont pas ajustées pour les comparaisons multiples. La fonction emmeans() du package emmeans permettra de générer les informations nécessaires pour faire les contrastes. La fonction pairs() calculera ces contrastes. Par défaut la méthode d’ajustement a posteriori pour comparaison multiple de Tukey-Kramer est utilisée.
library(emmeans)
contrast <- emmeans(modele, "par_cat") #Ici nous avons créé un objet nommé contrast qui contient les éléments dont nous aurons besoin pour comparer les catégories de par_cat
pairs(contrast) #Nous demandons ensuite les estimés des différentes catégories. ## contrast estimate SE df t.ratio p.value
## First - Second -715 42.5 1765 -16.848 <.0001
## First - Third or more -825 35.5 1765 -23.200 <.0001
## Second - Third or more -109 36.7 1765 -2.979 0.0082
##
## P value adjustment: tukey method for comparing a family of 3 estimatesNous voyons maintenant toutes les comparaisons possibles. Par exemple les vaches de 2ième lactation produisaient 109kg de lait de moins que les 3ième lactation. Et les valeurs de P présentées sont ajustées a posteriori pour les comparaisons multiples.Notez que vous pourriez aussi simplement faire un ajustement a priori (e.g. Bonferroni). Vous n’aurez pas alors à modifier le calcul des valeurs de P ou de vos IC 95%, mais simplement votre seuil α.
Si vous désirez plutôt l’estimé (i.e., le least square means) pour chaque catégorie et son intervalle de confiance, vous pouvez alors simplement utiliser la fonction confint() sur votre contraste:
confint(pairs(contrast))## contrast estimate SE df lower.CL upper.CL
## First - Second -715 42.5 1765 -815 -615.7
## First - Third or more -825 35.5 1765 -908 -741.3
## Second - Third or more -109 36.7 1765 -195 -23.3
##
## Confidence level used: 0.95
## Conf-level adjustment: tukey method for comparing a family of 3 estimatesOn verra alors les différences de production moyenne par catégorie et leurs IC 95. Par exemple, les vaches de 1ère lactation produisaient en moyenne 715kg de moins que les 2ième (IC 95: 616, 815). Ces IC 95 sont également ajustés pour les comparaisons multiples.
6.7 Évaluer une interaction entre 2 variables
L’interaction entre 2 variables peut être modélisée de manière très simple, vous n’avez qu’à indiquer dans votre modèle l’interaction entre les variables (parity x dyst). La fonction lm() se chargera alors d’inclure tous les termes nécessaires (i.e., dyst + parity + dyst x parity).
modele <- lm(data=daisy2_mod,
milk120 ~ (parity*dyst)) #parity*dyst demandera d'inclure dans le modèle: dyst + parity + dyst*parity
summary(modele)##
## Call:
## lm(formula = milk120 ~ (parity * dyst), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1970.32 -437.44 -17.17 422.63 2149.86
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2741.50 33.93 80.805 <2e-16 ***
## parity 169.51 10.27 16.506 <2e-16 ***
## dyst -89.58 115.00 -0.779 0.436
## parity:dyst 30.42 44.90 0.678 0.498
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 650.7 on 1764 degrees of freedom
## (208 observations effacées parce que manquantes)
## Multiple R-squared: 0.1455, Adjusted R-squared: 0.1441
## F-statistic: 100.1 on 3 and 1764 DF, p-value: < 2.2e-16anova(modele)## Analysis of Variance Table
##
## Response: milk120
## Df Sum Sq Mean Sq F value Pr(>F)
## parity 1 126939726 126939726 299.7720 <2e-16 ***
## dyst 1 64457 64457 0.1522 0.6965
## parity:dyst 1 194401 194401 0.4591 0.4981
## Residuals 1764 746973355 423454
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Ici, on voit les valeurs estimées du coefficient de chacun des paramètres du modèle et le test de F pour l’interaction (P=0.498).
C’est également possible de demander à voir un graphique illustrant cette interaction (ce sera parfois plus facile à interpréter). Le package sjPlot permet de générer toutes sortes de graphiques à partir de modèles estimés à l’aide des fonctions lm, glm, lme, lmerMod, etc. La fonction plot_model permet de générer une figure, j’indique le nom du modèle (dans ce cas, je l’avais simplement nommé modele) et le type de figure demandée. Ici je demande une figure int illustrant les effets des termes d’intéractions. La fonction plot_model cherchera les termes d’interaction dans le modèle et fera une figure à l’aide de ceux-ci. La variable apparaissant en premier dans le modèle sera utilisée pour l’axe des x. Pour plus de détails voir Plotting interaction effects of regression models.
library(sjPlot)
plot_model(modele, type="int")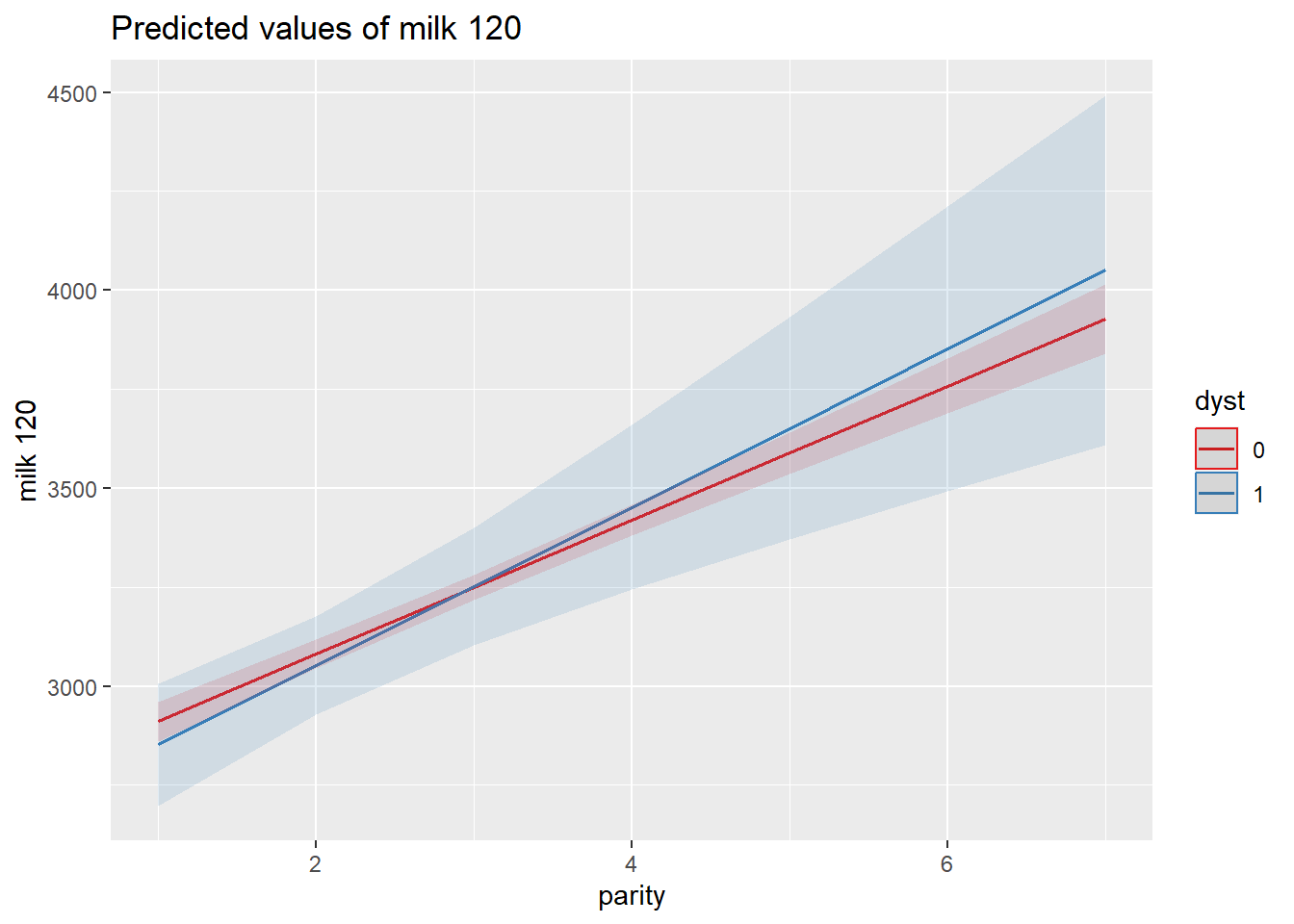
Figure 6.1: Effet de parité et dystocie sur la production laitière entre 0 et 120 jours en lait.
Notez que, si un de vos termes d’interaction est catégorique avec > 2 catégories et que vous avez utilisé la fonction factor() qui vous aura permis de bien identifier que cette variable est catégorique, les variables indicatrices seront alors créées automatiquement pour vous (ce qui sera très utile lorsque vous aurez des interactions avec des prédicteurs catégoriques avec > 2 catégories).
6.8 TOL et VIF - Évaluer la colinéarité
Afin de détecter les problèmes de colinéarité, on peut demander le calcul du « variance inflation factor » (VIF) à l’aide du package car et de la fonction vif(). La tolérance sera simplement (1/VIF). Un VIF > 10 (ou tolérance < 0.10) indiquera un problème sévère de colinéarité.
modele1<-lm(data=daisy2_mod,
milk120 ~ (dyst + parity)
)
library(car)
vif(modele1)## dyst parity
## 1.017337 1.017337On a donc un VIF de 1.02 (ou une tolérance de 0.98).
6.9 Évaluation du modèle
L’évaluation du modèle est basée sur différentes procédures diagnostiques. L’évaluation de graphiques constitue une part importante de ce travail.
6.9.1 Évaluer la linéarité de la relation à l’aide de courbes lissées (pour prédicteur quantitatif)
La linéarité de la relation est une supposition importante du modèle. Pour les prédicteurs quantitatifs, vous devrez toujours vérifier si cette supposition est bien respectée. Vous pouvez le faire à l’aide du modèle polynomial (en ajoutant le \(prédicteur^2\) ou le \(prédicteur^2\) et le \(prédicteur^3\) dans votre modèle; voir prochaine section). Si les coefficients de ces termes sont significativement différents de zéro (i.e. P < 0.05), ont concluera que la relation est une courbe, ou une courbe avec un ou plusieurs points d’inflexion, respectivement.
Mais une représentation graphique de la relation facilite toujours la compréhension. Les courbes lissées (e.g. loess, kernel) permettent de bien visualiser cette relation. Le package ggplot2 et les fonctions ggplot(), geom_point() et geom_smooth() vous permettent de réaliser ce genre de graphique. Le code suivant permet de visualiser la relation entre 2 variables continues (wpc et milk120). En jouant avec l’argument span vous pouvez changer le lissage de la courbe. Une petite valeur produira une courbe qui sautille beaucoup, une plus grande valeur produira une courbe plus lisse.
library(ggplot2)
ggplot(daisy2_mod, aes(wpc, milk120)) + #Ici nous avons simplement indiqué le jeu de données, puis les variables d'intérêt
geom_point() + #Nous demandons d'ajouter le nuage de points (un 'scatterplot')
geom_smooth(method="loess", span=2)+ #Nous demandons d'ajouter la courbe lissée de type loess. L'argument span nous permet d'ajuster le lissage
theme_bw() #C'est joli un fond blanc pour les figures (un thème noir et blanc: theme_bw()). C'est futile, mais bon...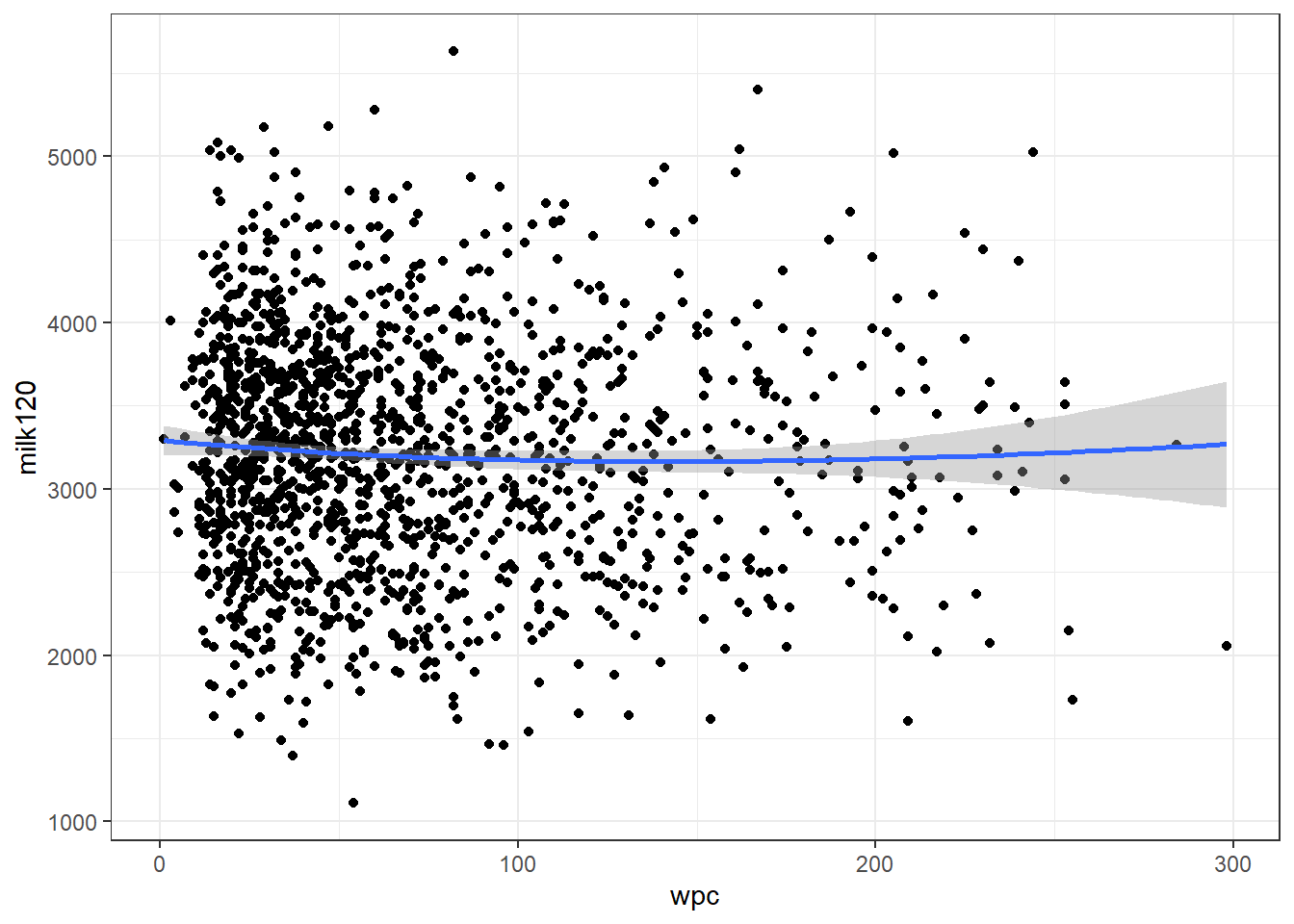
Figure 6.2: Relation entre le nombre de jours jusqu’à la saillie fécondante (wpc) et la production de lait en 120j (milk120) avec courbe lissée avec un facteur de 2.
Ici, la relation entre wpc et milk120 semble être une droite.
6.9.2 Évaluer la linéarité de la relation à l’aide de termes polynomiaux (pour prédicteur quantitatif)
Une autre manière d’évaluer la linéarité de la relation entre un prédicteur quantitatif et votre variable dépendante est de vérifier si des termes polynomiaux sont significatifs lorsque ajoutés au modèle. Par exemple, le modèle suivant suppose que la relation entre wpc et milk120 est une droite.
\[ milk120 = β_0 + β_1*wpc \]
En ajoutant une variable \(wpc^2\) au carré à ce modèle, nous permettons maintenant une relation curvilinéaire.
\[ milk120 = β_0 + β_1*wpc + β_2*wpc^2\]
Nous pourrions maintenant vérifier si le coefficient du terme \(wpc^2\) dans ce dernier modèle est statistiquement significatif. Si ce n’est pas le cas, nous avons alors confirmation que la relation est une droite. Si ce coefficient est statistiquement significatif, nous devons alors conclure à une relation curvilinéaire. Ce serait alors sage de vérifier s’il s’agit d’une simple courbe, ou plutôt d’une courbe avec un ou plusieurs points d’inflexion. Cela peut être fait en ajoutant un terme au cube, comme suit.
\[ milk120 = β_0 + β_*wpc + β_2*wpc^2 + β_3*wpc^3\]
Cette fois, nous évaluerons si le coefficent du terme \(wpc^3\) est statistiquement significatif. Si ce n’est pas le cas, nous avons alors confirmation que la relation est une simple courbe. Si ce coefficient est statistiquement significatif, nous devons alors conclure à une relation curvilinéaire avec un ou plusieurs points d’inflexion.
Dans R, deux options s’offrent à nous afin de vérifier ces modèles avec des termes polynomiaux. Nous pouvonc évidemment créer manuellement ces nouvelles variables au carré et au cube et les inclure dans le modèle. Cependant, la fonction poly() permet de créer automatiquement ces variables.
Par exemple, en créant manuellement les variables:
daisy2_mod$wpc_sq <- daisy2_mod$wpc*daisy2_mod$wpc
daisy2_mod$wpc_cu <- daisy2_mod$wpc*daisy2_mod$wpc*daisy2_mod$wpc
modele<-lm(data=daisy2_mod,
milk120 ~ (wpc + wpc_sq))
summary(modele)##
## Call:
## lm(formula = milk120 ~ (wpc + wpc_sq), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2103.49 -480.94 5.16 467.80 2439.52
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.282e+03 4.606e+01 71.266 <2e-16 ***
## wpc -1.568e+00 1.114e+00 -1.408 0.159
## wpc_sq 5.518e-03 5.094e-03 1.083 0.279
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 698 on 1533 degrees of freedom
## (440 observations effacées parce que manquantes)
## Multiple R-squared: 0.001738, Adjusted R-squared: 0.0004358
## F-statistic: 1.335 on 2 and 1533 DF, p-value: 0.2636Dans ce cas, nous voyons que le terme au carré n’est pas statistiquement significatif (P=0.279). Nous pourrions donc conclure que la relation entre wpc et milk120 est une droite. Dans ce cas, c’est alors inutile de vérifier le modèle avec termes au carré et au cube.
Nous pourrions obtenir les mêmes résultats avec la fonction poly():
modele<-lm(data=daisy2_mod,
milk120 ~ (poly(wpc,
degree=2, #degree=2 demande le terme principal + celui au carré. Avec degree=3, nous aurions alors les 3 termes
raw=TRUE)))
summary(modele)##
## Call:
## lm(formula = milk120 ~ (poly(wpc, degree = 2, raw = TRUE)), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2103.49 -480.94 5.16 467.80 2439.52
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.282e+03 4.606e+01 71.266 <2e-16 ***
## poly(wpc, degree = 2, raw = TRUE)1 -1.568e+00 1.114e+00 -1.408 0.159
## poly(wpc, degree = 2, raw = TRUE)2 5.518e-03 5.094e-03 1.083 0.279
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 698 on 1533 degrees of freedom
## (440 observations effacées parce que manquantes)
## Multiple R-squared: 0.001738, Adjusted R-squared: 0.0004358
## F-statistic: 1.335 on 2 and 1533 DF, p-value: 0.26366.9.3 Méthodes diagnostiques pour les résiduels
La fonction plot() demande les principaux graphiques qui serviront à évaluer l’adéquation du modèle (i.e. l’homoscédasticité et la normalité des résiduels).
Les plus intéressants sont probablement :
• Le graphique des Résiduels x valeurs prédites (Residual vs Fitted). Ce graphique vous permettra de visualiser si la variance est homogène en fonction des valeurs prédites. On désire une « bande » horizontale égale (semble assez problématique pour cet exemple; la bande va en augmentant)
• Le graphique des quantiles x résiduels (Normal Q-Q) permet d’évaluer la normalité des résiduels. On désire que les points forment une ligne de 45º qui se superpose à la ligne pointillée dans la figure (encore assez problématique dans cet exemple)
modele2 <- lm(data=daisy2_mod,
wpc ~ (dyst + parity + herd_size + twin)
)
plot(modele2, 1) #Nous demandons la première figure du 'pannel plot' de diagnostique (c'est la figure Residual vs Fitted)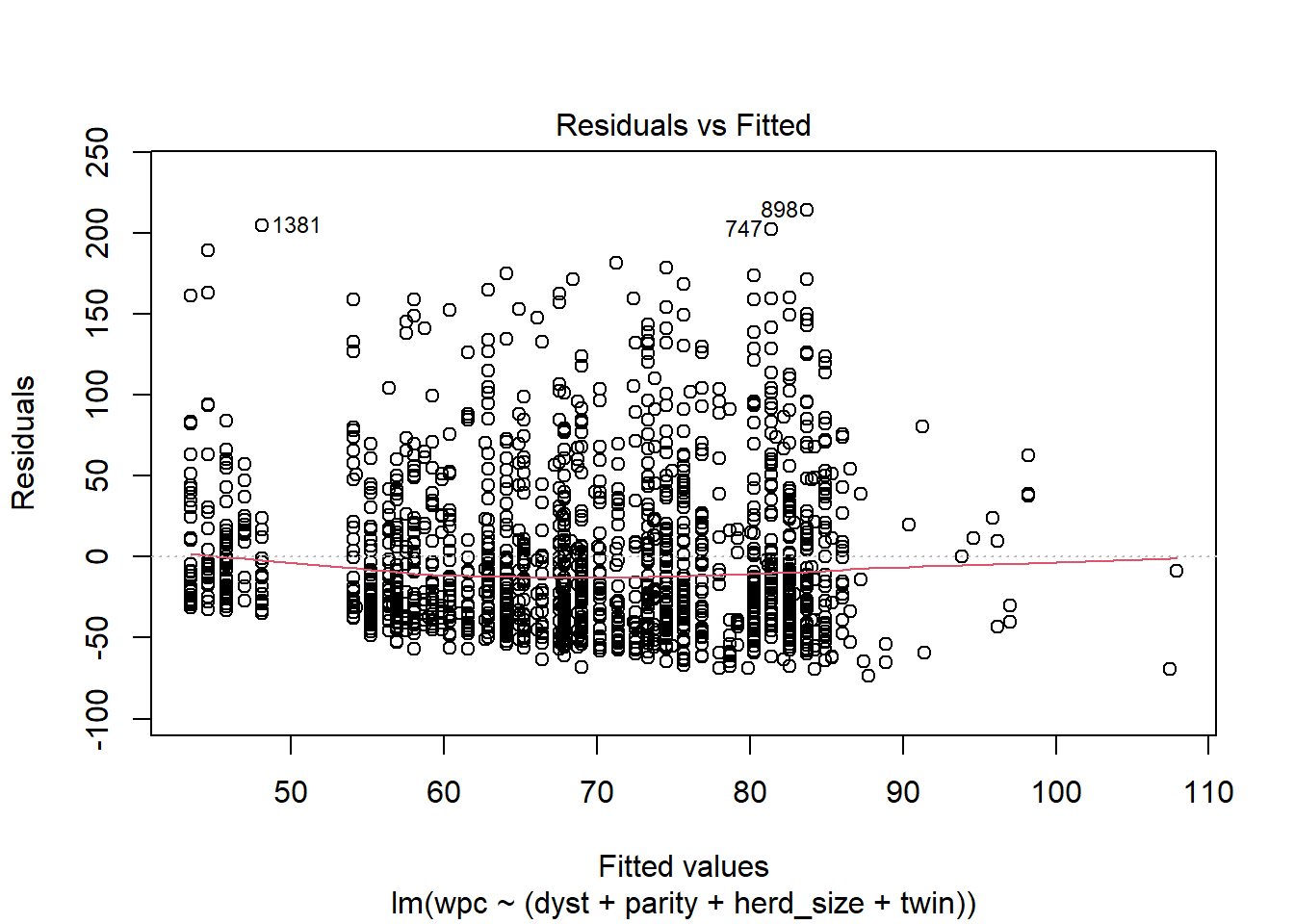
Figure 6.3: Graphique des résiduels x valeurs prédites.
plot(modele2, 2) #Nous demandons la 2ième figure du 'pannel plot' de diagnostique (c'est la figure Normal Q-Q)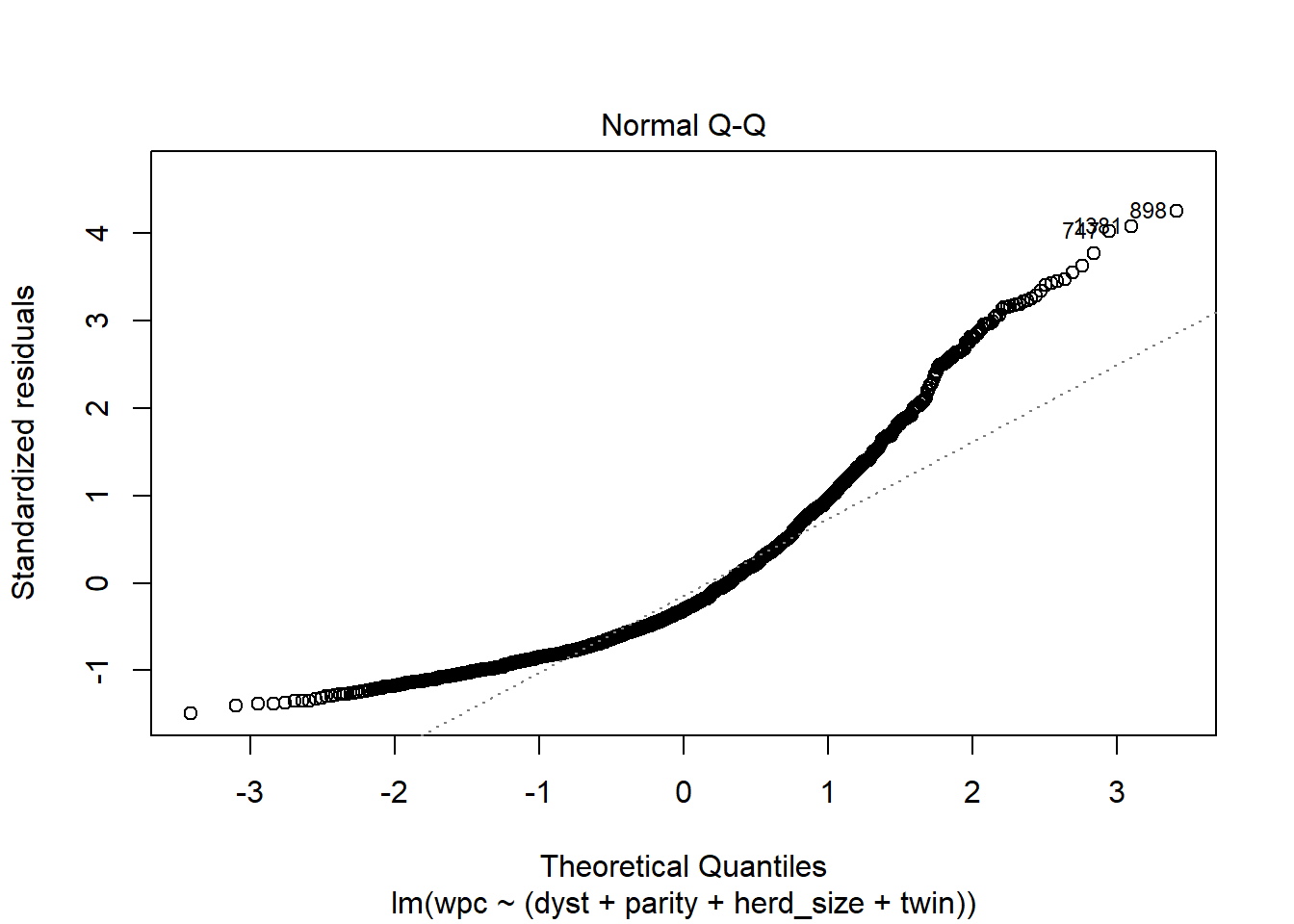
Figure 6.4: Graphique Q-Q des résiduels.
#Alternativement, nous pourrions ne pas spécifier les figures qui nous intéressent et simplement tout demander ainsi:
#plot(modele2)
#Vous aurez alors toute la série (n=4) de graphiques6.9.4 Évaluation des observations extrêmes et/ou influentes
Certaines observations peuvent être très différentes des autres et avoir un effet important sur les résultats de la régression. Cette observation peut être une observation extrême (outlier), c’est-à-dire une observation avec une combinaison inhabituelle de valeurs pour la variable dépendante et les variables indépendantes. Ce peut être une observation avec une valeur extrême pour un prédicteur, que l’on appelle variable à effet levier (leverage). Enfin ce peut être une observation qui, si elle est soustraite à l’analyse, change substantiellement les estimés des coefficients (influence).
Dans R, vous pouvez facilement ajouter dans votre base de données les valeurs prédites par le modèle, les résiduels, les distances de Cook, les leviers, etc avec la fonction augment() du package broom. Vous pourrez ensuite trier cette table pour identifier, par exemple, les observations avec les résiduels, les leviers ou les distances de Cook les plus extrêmes et essayer de comprendre si ces observations ont quelque chose en commun.
library(broom)
diag <- augment(modele2) #Nous avons créé une nouvelle table dans laquelle les résiduels, distance de cook, etc se trouvent maintenant
head(diag)## # A tibble: 6 × 12
## .rown…¹ wpc dyst parity herd_…² twin .fitted .resid .hat .sigma .cooksd
## <chr> <int> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 3 67 0 5 294 0 78.0 -11.0 0.00239 50.4 2.30e-5
## 2 4 9 0 5 294 0 78.0 -69.0 0.00239 50.4 9.01e-4
## 3 5 61 0 5 294 0 78.0 -17.0 0.00239 50.4 5.48e-5
## 4 8 117 0 5 294 0 78.0 39.0 0.00239 50.4 2.87e-4
## 5 9 36 0 6 294 0 79.2 -43.2 0.00397 50.4 5.88e-4
## 6 11 19 0 5 294 0 78.0 -59.0 0.00239 50.4 6.59e-4
## # … with 1 more variable: .std.resid <dbl>, and abbreviated variable names
## # ¹.rownames, ²herd_sizeLes nouvelles variables correspondent à:
- Valeur prédite (.fitted)
- Résiduel (.resid)
- Levier (.hat)
- Distance de Cook (.cooksd)
- Résiduel standardisé (.std.resid)
À l’aide de la fonction ggplot vous pourrez alors produire les graphiques qui vous intéressent. Par exemple :
ggplot(diag,
aes(x=wpc,
y=.std.resid,
colour=.std.resid)
) + #Nous indiquons les variables d'intérêt. Nous nous sommes permis une petite fantaisie ici, nous modifions la couleur des points en fonction de la valeur du résiduel standardisé
geom_point() + #Nous demandons un graphique nuage de points
geom_hline (aes(yintercept=3)) + #Une autre fantaisie, ajoutons des barres horizontales qui permettent de marquer les valeurs -3 et +3 (pour identifier les résiduels 'extrêmes')
geom_hline (aes(yintercept=-3)) +
theme_bw() #Le fameux fond blanc!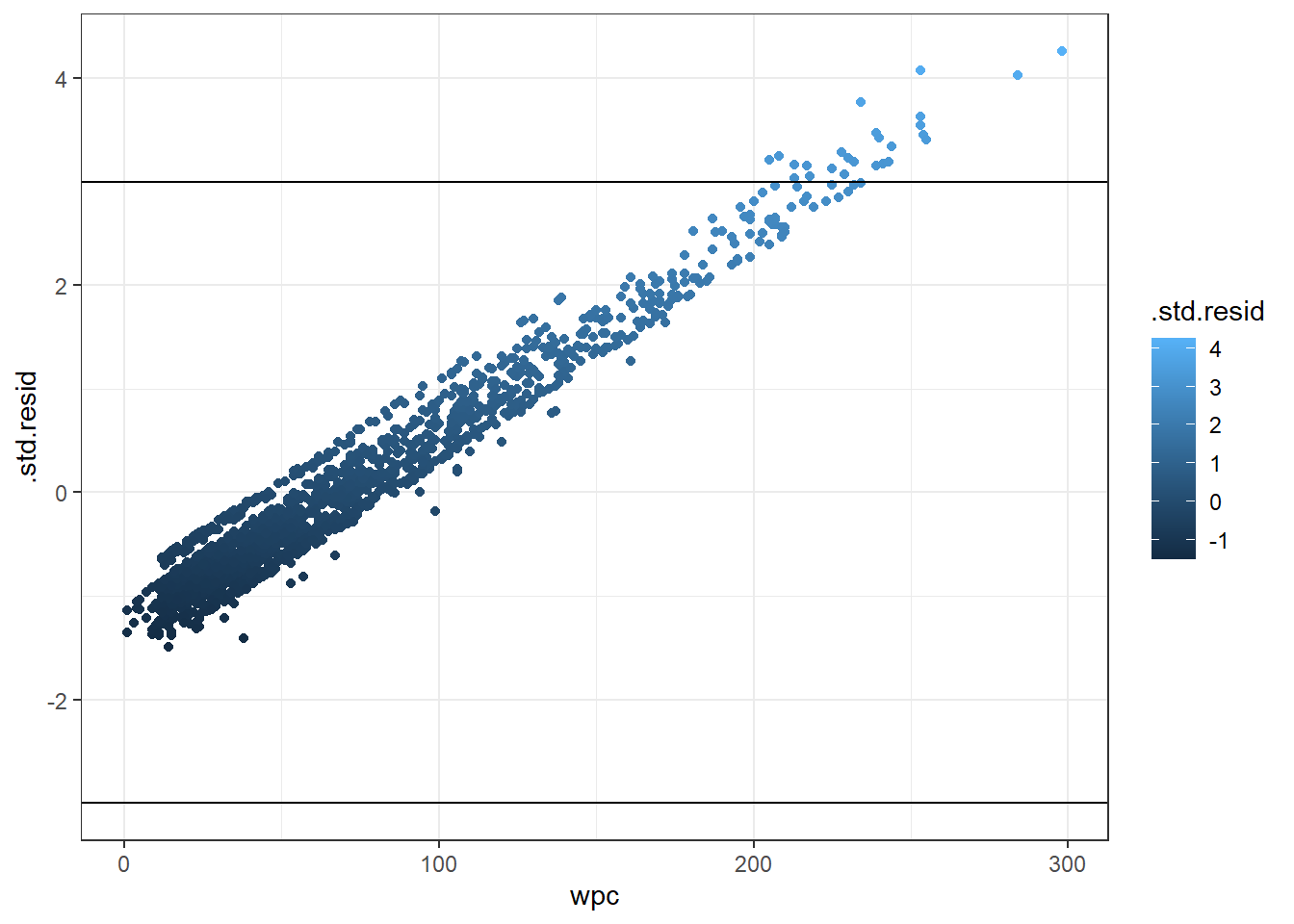
Figure 6.5: Graphique des résiduels de Student par jours jusqu’à la saillie fécondante (wpc).
Dans ce cas, on voit que seulement les vaches avec un WPC long (> 250j) ont des résiduels larges (i.e. > 3.0 ou < -3.0). Le modèle semble donc avoir de la difficulté à bien prédire ces observations.
6.10 Travaux pratiques 1 - Régression linéaire - Base
6.10.1 Exercices
Pour ce TP utilisez le fichier DAISY2 (voir description VER p.809).
Ne sélectionnez que les 7 troupeaux avec h7=1.
1) Considérons le nombre de jours jusqu’à la saillie fécondante (WPC) comme variable dépendante et vérifions comment différents prédicteurs permettent de prédire cet intervalle.
a. Représentez graphiquement l’association entre milk120 et WPC. Pensez-vous qu’une ligne droite passant au travers des points capture adéquatement la relation entre ces deux variables ?
b. Faites varier le lissage (e.g. 0.1 ou 1) et décrivez comment la courbe lissée change en fonction de ce lissage.
c. Maintenant, représentez graphiquement la relation entre parity et wpc. Dans ce cas, pensez-vous qu’une ligne droite passant au travers des points capture adéquatement la relation entre ces deux variables ?
d. À partir du diagramme de dispersion, il est raisonnable de penser que l’intervalle WPC change linéairement avec parity. Cette relation linéaire peut être exprimée par le modèle \(WPC= β_0 + β_1*parity\). À l’aide d’un modèle de régression linéaire, estimez les valeurs de \(β_0\) et \(β_1\). Écrivez l’équation de régression sous la forme donnée ci-dessus, avec ces estimés dans l’équation. Comment interprétez-vous ces estimés ?
e. Un test de F vous est rapporté pour le modèle de même qu’un test de T pour le coefficient de régression de parity (i.e. \(β_1\)). Quelles sont les hypothèses nulles pour chacun de ces tests? Dans ce cas, ces 2 tests sont-ils réellement différents?
f. Quel serait l’IC95% pour le coefficient de régression de parity?
g. Existe-t-il une relation linéaire statistiquement significative entre ces 2 variables?
h. Le nombre de jours jusqu’à la saillie fécondante (WPC) pour une vache de parité zéro n’a, bien sûr, pas de sens biologique. Pour repositionner ce paramètre à la parité minimale observée (i.e. parity=1), on peut remplacer la parité par une nouvelle variable (parity_ct) centrée sur parity=1. Créez cette nouvelle variable et, à l’aide d’un modèle de régression linéaire, estimez les valeurs de \(β_0\) et \(β_1\) et interprétez les coefficients de régression comme à la question 1.d.
2) À la question 1.a, nous avons vu que la relation entre milk120 et WPC ne semble pas être linéaire. Nous pourrions donc créer des termes polynomiaux afin de modéliser correctement cette association.
a. Créez une nouvelle variable milk120_ct centrée sur la production moyenne. Puis créez 1 terme polynomial milk120_ct_sq (i.e. milk120 au carré). Vérifiez si l’ajout d’une courbe (i.e. le terme au carré) ajoute significativement au modèle.
b. Selon votre analyse graphique réalisée à la question 1.a, pensez-vous que vous auriez besoin d’ajouter d’autres points d’inflexion pour bien représenter cette association? Vérifiez votre réponse en ajoutant un terme au cube pour milk120 en plus du terme au carré.
c. Dans ce dernier modèle, vérifiez qu’il n’y a pas de problème sévère de colinéarité.
3) Dans le modèle suivant \(wpc = β_0 +β_1*parityct + β_2*twin + β_3*dyst\) vous vous demandez si les problèmes de vêlage (i.e. twin et dyst ensemble) apportent significativement au modèle. Quel test pourriez-vous réaliser afin de répondre à cette question? Quel est le résultat de ce test et votre interprétation de ce résultat?
4) Recodez maintenant parity afin d’avoir une nouvelle variable catégorique (parity_cat) à 3 niveaux (parity 1, parity 2 et parity ≥3). Vérifiez la relation entre parity_cat et WPC en vous assurant d’avoir parity 1 comme valeur de référence.
a. Est-ce que parity_cat (comme variable) est significativement associée à WPC?
b. De combien WPC change pour une vache de 2ième parité comparativement à une vache de 1ère parité?
c. Quel est le WPC pour une vache de 1ère parité?
d. Quelle est la différence de WPC entre une vache de 2ième et une de 3ième parité et quel est l’IC 95% ajusté pour comparaisons multiples pour cette différence? Cette différence est-elle statistiquement significative?
5) Vous supposez que l’effet d’une dystocie (dyst) sur WPC varie en fonction de la parité (catégorique 1ère, 2ième, ou ≥3ième). Par exemple, une vache plus vieille ayant une dystocie aura possiblement un délai plus long jusqu’à la saille fécondante comparativement à une vache plus jeune.
a. Que devrez-vous tester pour vérifier cette hypothèse?
b. Effectuez ce test. Est-ce que l’effet de dystocie varie de manière statistiquement significative en fonction de la parité?
c. Quel est le nombre de jours moyen jusqu’à la saillie fécondante pour chacune des catégories de parité et de dystocie (i.e. remplir le tableau suivant)? Pour quel niveau de parité les différences semblent les plus importantes?
| Parite | Dystocie_0 | Dystocie_1 |
|---|---|---|
| 1ère lactation | ||
| 2ième lactation | ||
| 3ième ou plus |
6.10.2 Code R et réponses
Pour ce TP utilisez le fichier DAISY2 (voir description VER p.809).
Ne sélectionnez que les 7 troupeaux avec h7=1.
#Ouvrir le jeu de données
daisy2 <-read.csv(file="daisy2.csv",
header=TRUE,
sep=",")
#Sélectionner les 7 troupeaux
daisy2_mod<-subset(daisy2,
h7==1)1) Considérons le nombre de jours jusqu’à la saillie fécondante (WPC) comme variable dépendante et vérifions comment différents prédicteurs permettent de prédire cet intervalle.
a. Représentez graphiquement l’association entre milk120 et WPC. Pensez-vous qu’une ligne droite passant au travers des points capture adéquatement la relation entre ces deux variables ?
library(ggplot2)
ggplot(daisy2_mod,
aes(milk120, wpc)
) +
geom_point() +
geom_smooth(method="loess",
span=2) +
theme_bw() 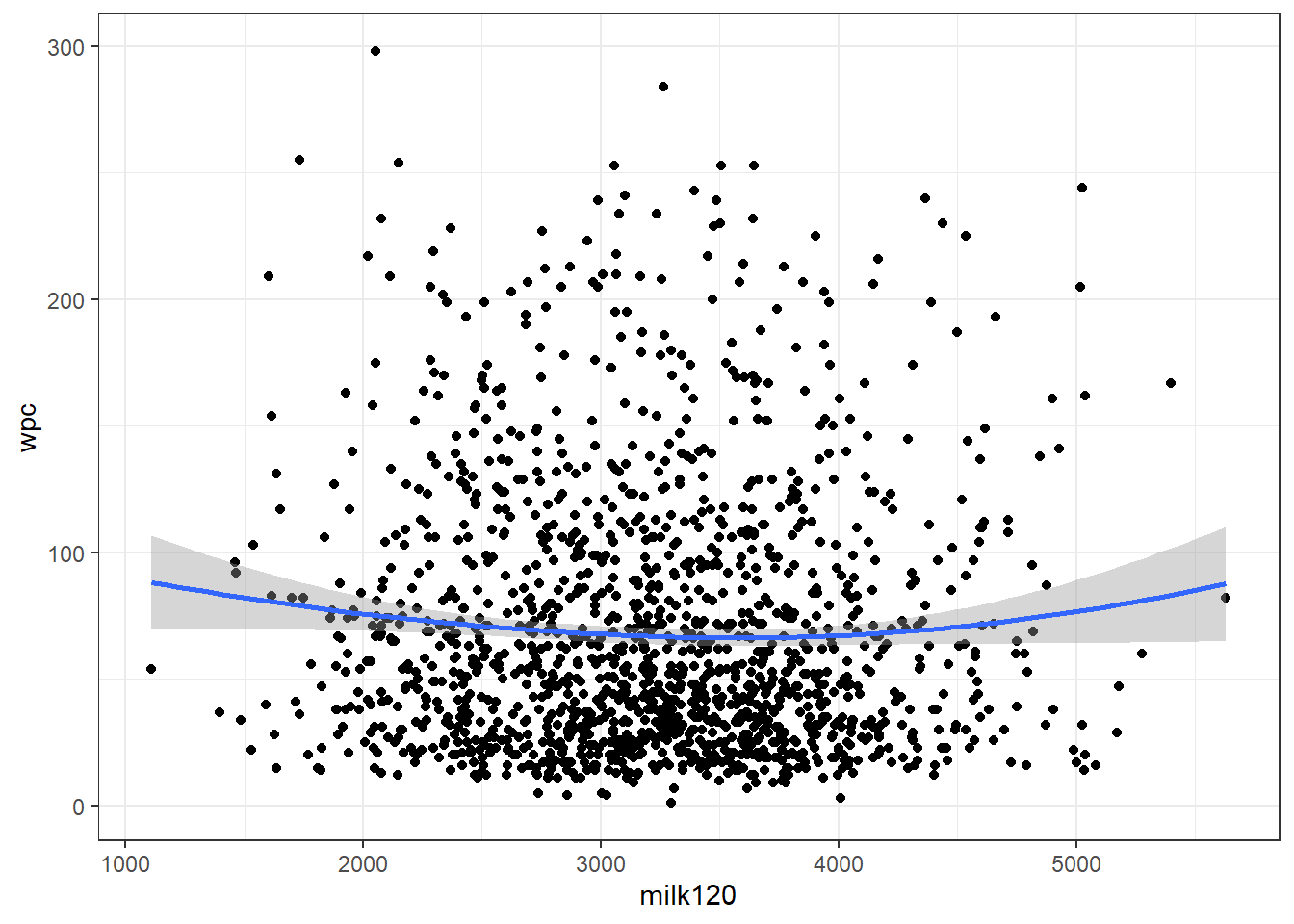
Figure 6.6: Relation entre la production de lait en 120j (milk120) et le nombre de jours jusqu’à la saillie fécondante (wpc) avec courbe lissée avec un facteur de 2.
Réponse: Non, relation semble légèrement curvilinéaire
b. Faites varier le lissage (e.g. 0.1 ou 1) et décrivez comment la courbe lissée change en fonction de ce lissage.
ggplot(daisy2_mod,
aes(milk120, wpc)
) +
geom_point() +
geom_smooth(method="loess",
span=0.2) +
theme_bw() 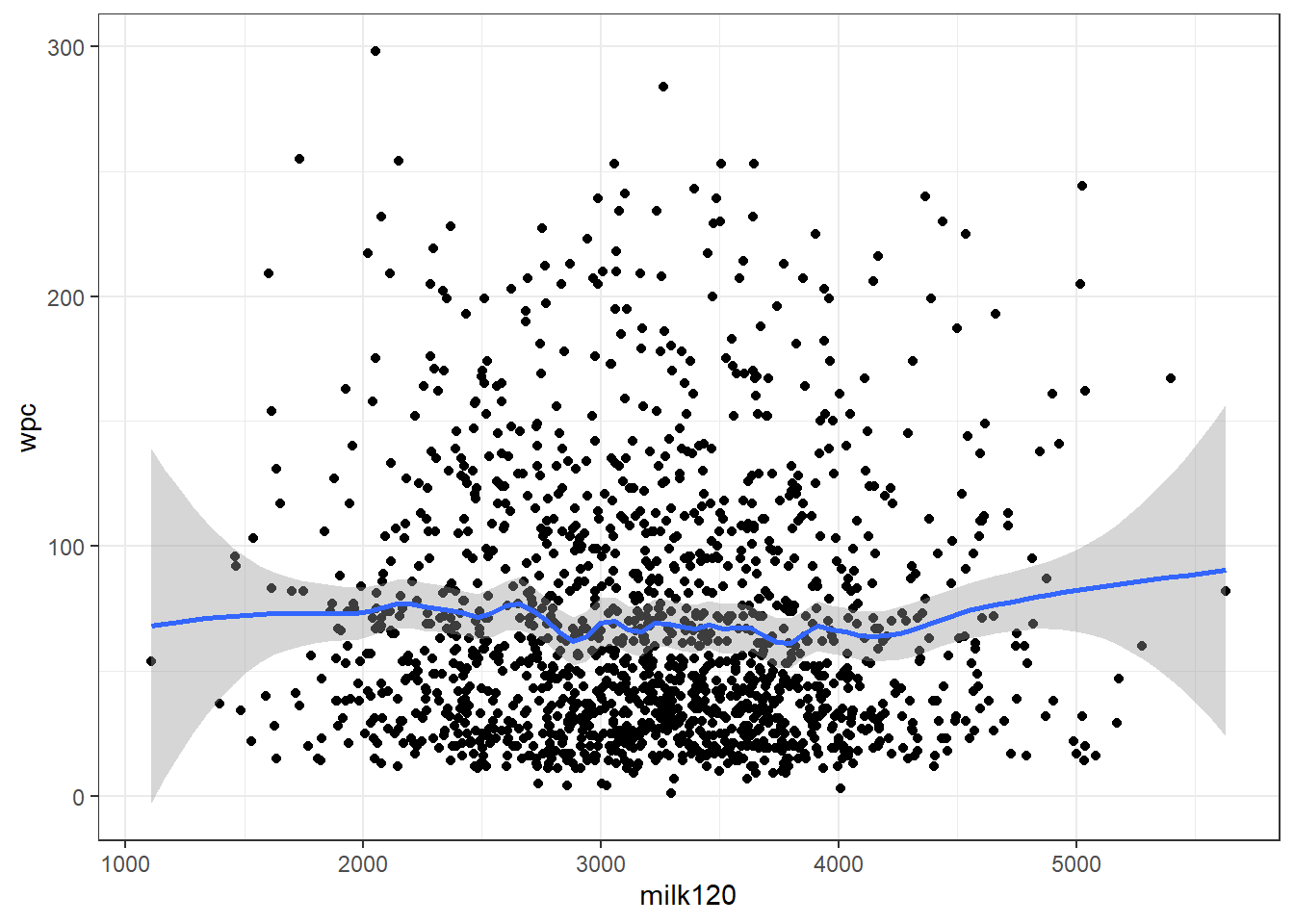
Figure 6.7: Relation entre la production de lait en 120j (milk120) et le nombre de jours jusqu’à la saillie fécondante (wpc) avec courbe lissée avec un facteur de 0.2.
Réponse: Lorsqu’on réduit le span, la courbe permet de visualiser toutes les petites variations. Elle devient plus droite (i.e. moins sensible aux variations locales) lorsque le span augmente.
c. Maintenant, représentez graphiquement la relation entre parity et wpc. Dans ce cas, pensez-vous qu’une ligne droite passant au travers des points capture adéquatement la relation entre ces deux variables ?
ggplot(daisy2_mod,
aes(parity, wpc)
) +
geom_point() +
geom_smooth(method="loess",
span=2) +
theme_bw() 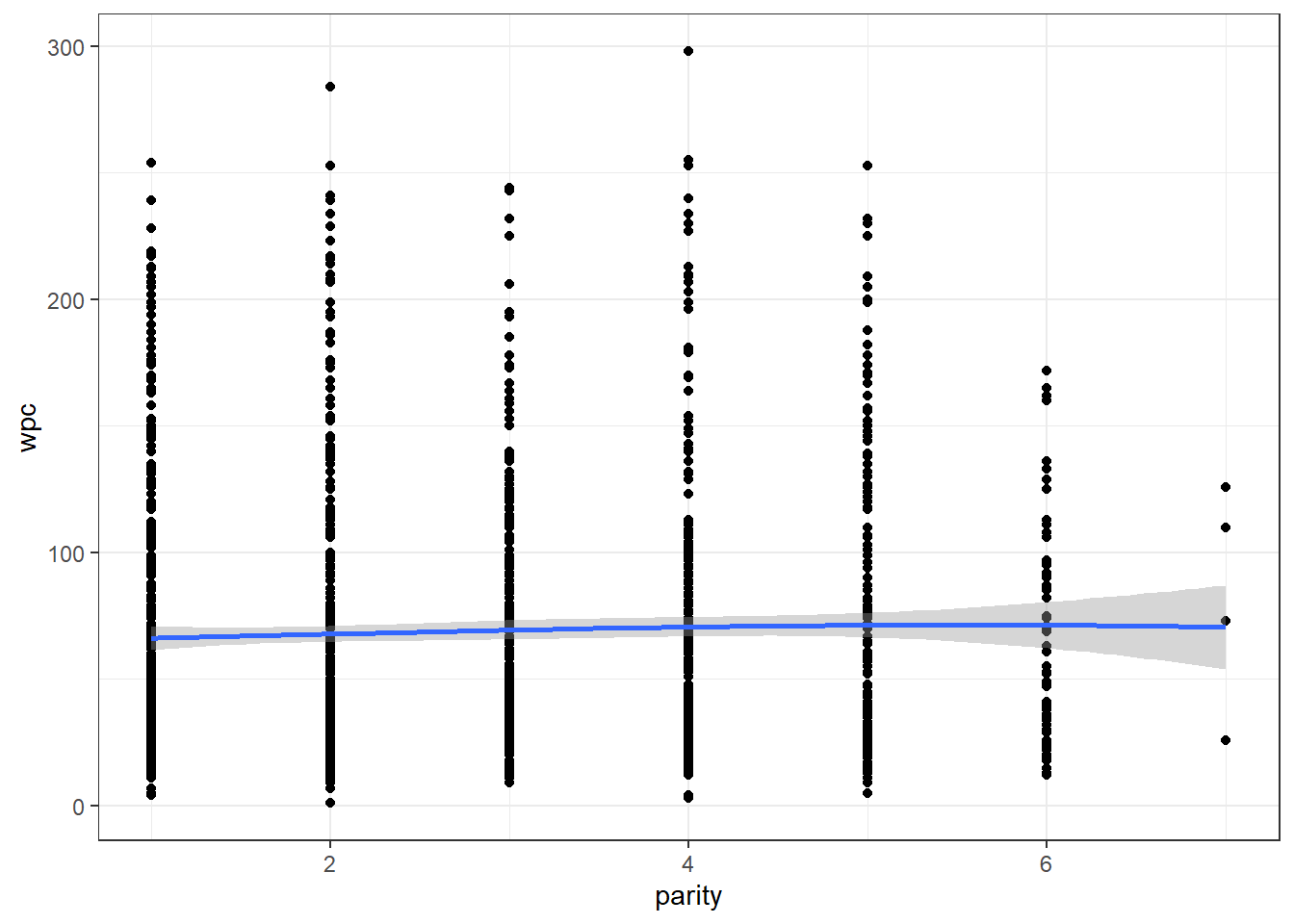
Figure 6.8: Relation entre parité (parity) et le nombre de jours jusqu’à la saillie fécondante (wpc) avec courbe lissée avec un facteur de 2.
Réponse: Oui, semble mieux
d. À partir du diagramme de dispersion, il est raisonnable de penser que l’intervalle WPC change linéairement avec parity. Cette relation linéaire peut être exprimée par le modèle \(WPC= β_0 + β_1*parity\). À l’aide d’un modèle de régression linéaire, estimez les valeurs de \(β_0\) et \(β_1\). Écrivez l’équation de régression sous la forme donnée ci-dessus, avec ces estimés dans l’équation. Comment interprétez-vous ces estimés ?
modele1<-lm(data=daisy2_mod,
wpc ~ (parity)
)
modele1 ##
## Call:
## lm(formula = wpc ~ (parity), data = daisy2_mod)
##
## Coefficients:
## (Intercept) parity
## 65.218 1.312Réponse: \(WPC= 65.2 + 1.3*parity\)
Intervalle WPC moyen quand parité=0 est de 65.2j. On ajoute ensuite 1.3 jours à chaque fois qu’on ajoute une parité.
e. Un test de F vous est rapporté pour le modèle de même qu’un test de T pour le coefficient de régression de parity (i.e. \(β_1\)). Quelles sont les hypothèses nulles pour chacun de ces tests? Dans ce cas, ces 2 tests sont-ils réellement différents?
summary(modele1)##
## Call:
## lm(formula = wpc ~ (parity), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -67.47 -38.47 -15.15 24.16 227.53
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 65.2181 2.7090 24.075 <2e-16 ***
## parity 1.3118 0.8706 1.507 0.132
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 51.58 on 1572 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.001442, Adjusted R-squared: 0.000807
## F-statistic: 2.271 on 1 and 1572 DF, p-value: 0.1321Réponse: Test de F (P=0.132): tous les coefficients (outre \(β_0\), l’intercept) = 0
Test de T (aussi P=0.132): le coefficient de parity (\(β_1\)) = 0
Non, puisqu’il y a un seul coefficient de régression dans l’équation les 2 tests sont équivalents.
f. Quel serait l’IC95% pour le coefficient de régression de parity?
confint(modele1)## 2.5 % 97.5 %
## (Intercept) 59.9045164 70.531662
## parity -0.3958026 3.019367Réponse: -0.4 à 3.0 jours
g. Existe-t-il une relation linéaire statistiquement significative entre ces 2 variables?
Réponse: Non (P=0.13 et l’IC95% inclus la valeur 0)
h. Le nombre de jours jusqu’à la saillie fécondante (WPC) pour une vache de parité zéro n’a, bien sûr, pas de sens biologique. Pour repositionner ce paramètre à la parité minimale observée (i.e. parity=1), on peut remplacer la parité par une nouvelle variable (parity_ct) centrée sur parity=1. Créez cette nouvelle variable et, à l’aide d’un modèle de régression linéaire, estimez les valeurs de \(β_0\) et \(β_1\) et interprétez les coefficients de régression comme à la question 1.d.
daisy2_mod$par_ct <- daisy2_mod$parity-1
modele2<-lm(data=daisy2_mod,
wpc ~ (par_ct)
)
modele2##
## Call:
## lm(formula = wpc ~ (par_ct), data = daisy2_mod)
##
## Coefficients:
## (Intercept) par_ct
## 66.530 1.312Réponse: Intervalle wpc moyen quand parité=1 est de 66.5j. On ajoute ensuite 1.3 jours à chaque fois qu’on ajoute une parité.
2) À la question 1.a, nous avons vu que la relation entre milk120 et WPC ne semble pas être linéaire. Nous pourrions donc créer des termes polynomiaux afin de modéliser correctement cette association.
a. Créez une nouvelle variable milk120_ct centrée sur la production moyenne. Puis créez 1 terme polynomial milk120_ct_sq (i.e. milk120 au carré). Vérifiez si l’ajout d’une courbe (i.e. le terme au carré) ajoute significativement au modèle.
#Vérifions d'abord quelle est la moyenne de milk120
mean(daisy2_mod$milk120,
na.rm=TRUE)## [1] 3225.311#Nous créons ensuite la variable centrée sur 3225 et celle au carré
daisy2_mod$milk120_ct <- daisy2_mod$milk120-3225
daisy2_mod$milk120_ct_sq <-daisy2_mod$milk120_ct*daisy2_mod$milk120_ct
#Vérifions que ça a bien fonctionné
head(daisy2_mod)## region herd cow study_lact herd_size mwp parity milk120 calv_dt cf fs cc
## 1 1 1 1 1 294 26 5 3505.8 1996-11-11 80 NA NA
## 2 1 1 2 1 294 26 5 3691.3 1997-01-12 64 NA NA
## 3 1 1 3 1 294 26 5 4173.0 1997-01-17 71 0 93
## 4 1 1 4 1 294 26 5 3727.3 1997-02-11 35 1 35
## 5 1 1 5 1 294 26 5 3090.8 1997-06-26 47 0 87
## 6 1 1 6 1 294 26 4 5041.2 1996-10-16 NA NA NA
## wpc spc twin dyst rp vag_disch h7 par_ct milk120_ct milk120_ct_sq
## 1 NA 6 0 0 0 0 1 4 280.8 78848.67
## 2 NA 3 0 0 0 0 1 4 466.3 217435.74
## 3 67 2 0 0 0 0 1 4 948.0 898704.00
## 4 9 1 0 0 0 0 1 4 502.3 252305.34
## 5 61 2 0 0 0 0 1 4 -134.2 18009.63
## 6 NA NA 0 0 1 0 1 3 1816.2 3298583.15#Vérifions le modèle avec les termes polynomiaux
modele3<-lm(data=daisy2_mod,
wpc ~ (milk120_ct+milk120_ct_sq)
)
summary(modele3)##
## Call:
## lm(formula = wpc ~ (milk120_ct + milk120_ct_sq), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -66.34 -38.70 -15.26 25.28 222.44
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.697e+01 1.639e+00 40.856 <2e-16 ***
## milk120_ct -2.545e-03 1.892e-03 -1.345 0.1787
## milk120_ct_sq 4.089e-06 1.998e-06 2.046 0.0409 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 51.65 on 1533 degrees of freedom
## (440 observations effacées parce que manquantes)
## Multiple R-squared: 0.003696, Adjusted R-squared: 0.002396
## F-statistic: 2.843 on 2 and 1533 DF, p-value: 0.05854Réponse: Oui, le terme au carré est significativement associé (i.e. P = 0.04) à wpc. Donc le terme représentant la courbe à un coefficient différent de 0.
b. Selon votre analyse graphique réalisée à la question 1.a, pensez-vous que vous auriez besoin d’ajouter d’autres points d’inflexion pour bien représenter cette association? Vérifiez votre réponse en ajoutant un terme au cube pour milk120 en plus du terme au carré.
Réponse: a priori, ça semblait être une simple courbe.
#Nous créons une variable milk120 à la puissance 3
daisy2_mod$milk120_ct_cu <-daisy2_mod$milk120_ct_sq*daisy2_mod$milk120_ct
#Nous l'ajoutons au modèle
modele4<-lm(data=daisy2_mod,
wpc ~ (milk120_ct+milk120_ct_sq+milk120_ct_cu)
)
summary(modele4)##
## Call:
## lm(formula = wpc ~ (milk120_ct + milk120_ct_sq + milk120_ct_cu),
## data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -68.71 -38.40 -15.64 25.59 223.22
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.724e+01 1.650e+00 40.761 <2e-16 ***
## milk120_ct -6.171e-03 3.163e-03 -1.951 0.0513 .
## milk120_ct_sq 3.330e-06 2.067e-06 1.611 0.1073
## milk120_ct_cu 2.651e-09 1.854e-09 1.430 0.1530
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 51.63 on 1532 degrees of freedom
## (440 observations effacées parce que manquantes)
## Multiple R-squared: 0.005023, Adjusted R-squared: 0.003075
## F-statistic: 2.578 on 3 and 1532 DF, p-value: 0.05222Effectivement, on obtient P=0.15 pour le terme au cube (i.e. n’ajoute rien au modèle).
c. Dans ce dernier modèle, vérifiez qu’il n’y a pas de problème sévère de colinéarité.
library(car)
vif(modele4)## milk120_ct milk120_ct_sq milk120_ct_cu
## 2.808468 1.074436 2.918711Réponse: Les VIF sont tous < 10, donc pas de problème.
3) Dans le modèle suivant \(wpc = β_0 +β_1*parityct + β_2*twin + β_3*dyst\) vous vous demandez si les problèmes de vêlage (i.e. twin et dyst ensemble) apportent significativement au modèle. Quel test pourriez-vous réaliser afin de répondre à cette question? Quel est le résultat de ce test et votre interprétation de ce résultat?
Réponse: Test de F pour comparer modèle complet (i.e. parity_ct, twin et dyst) vs. modèle réduit (i.e. parity_ct).
modele_complet <- lm(data=daisy2_mod,
wpc ~ (par_ct+twin+dyst)
)
modele_reduit <- lm(data=daisy2_mod,
wpc ~ (par_ct)
)
anova(modele_complet,
modele_reduit)## Analysis of Variance Table
##
## Model 1: wpc ~ (par_ct + twin + dyst)
## Model 2: wpc ~ (par_ct)
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 1570 4167004
## 2 1572 4182050 -2 -15046 2.8345 0.05905 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1P =0.06, donc ces variables, ensemble, n’apportent pas au modèle (i.e. les coefficients de régression ne sont pas différents de 0).
4) Recodez maintenant parity afin d’avoir une nouvelle variable catégorique (parity_cat) à 3 niveaux (parity 1, parity 2 et parity ≥3). Vérifiez la relation entre parity_cat et WPC en vous assurant d’avoir parity 1 comme valeur de référence.
#Nous créons une variable parity catégorique:
daisy2_mod$par_cat <- cut(daisy2_mod$parity,
breaks = c(0, 1, 2, Inf),
labels = c("First", "Second", "Third or more")
)
#Nous fixons le niveau de référence et l'ajoutons au modèle
daisy2_mod<-within(daisy2_mod,
par_cat <- relevel(par_cat,
ref="First")) #Sélection de la valeur de référence par_cat=1
modele5 <- lm(data=daisy2_mod,
wpc ~ (par_cat)
)
summary(modele5)##
## Call:
## lm(formula = wpc ~ (par_cat), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -67.54 -38.21 -15.54 24.46 227.46
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 66.9520 2.5270 26.495 <2e-16 ***
## par_catSecond 0.2592 3.6750 0.071 0.944
## par_catThird or more 3.5895 3.1284 1.147 0.251
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 51.6 on 1571 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.001132, Adjusted R-squared: -0.0001392
## F-statistic: 0.8905 on 2 and 1571 DF, p-value: 0.4106a. Est-ce que parity_cat (comme variable) est significativement associée à WPC?
Réponse: Non, le test de F qui teste tous les coefficients ensemble donne P=0.41
b. De combien WPC change pour une vache de 2ième parité comparativement à une vache de 1ère parité?
Réponse: +0.3 jours
c. Quel est le WPC pour une vache de 1ère parité?
Réponse: 67.0 jours
d. Quelle est la différence de WPC entre une 2ième et une 3ième parité et quel est l’IC 95% ajusté pour comparaisons multiples pour cette différence? Cette différence est-elle statistiquement significative?
library(emmeans)
contrast <- emmeans(modele5,
"par_cat") #Ici nous créons un objet nommé contrast qui contient les éléments dont nous aurons besoin pour comparer les catégories de par_cat
pairs(contrast) #Nous demandons ensuite de comparer les différentes catégories. ## contrast estimate SE df t.ratio p.value
## First - Second -0.259 3.68 1571 -0.071 0.9973
## First - Third or more -3.589 3.13 1571 -1.147 0.4850
## Second - Third or more -3.330 3.24 1571 -1.027 0.5601
##
## P value adjustment: tukey method for comparing a family of 3 estimates#Pour voir les intervalles de confiance, nous pourrons demander un confint() sur cette fonction pairs()
confint(pairs(contrast))## contrast estimate SE df lower.CL upper.CL
## First - Second -0.259 3.68 1571 -8.88 8.36
## First - Third or more -3.589 3.13 1571 -10.93 3.75
## Second - Third or more -3.330 3.24 1571 -10.94 4.28
##
## Confidence level used: 0.95
## Conf-level adjustment: tukey method for comparing a family of 3 estimatesRéponse: 3.3 jours de plus pour une 3ième parité (vs. 2ième). IC95: -4.3 à 10.9 jours de plus. Ce n’est pas une différence statistiquement significative (la valeur zéro est incluse dans l’IC95).
5) Vous supposez que l’effet d’une dystocie (dyst) sur WPC varie en fonction de la parité (catégorique 1ère, 2ième, ou ≥3ième). Par exemple, une vache plus vieille ayant une dystocie aura possiblement un délai plus long jusqu’à la saille fécondante comparativement à une vache plus jeune.
a. Que devrez-vous tester pour vérifier cette hypothèse?
Réponse: L’interaction entre dyst et par_cat.
b. Effectuez ce test. Est-ce que l’effet de dystocie varie de manière statistiquement significative en fonction de la parité?
modele6 <- lm(data=daisy2_mod,
wpc ~ (par_cat*dyst)
)
summary(modele6)##
## Call:
## lm(formula = wpc ~ (par_cat * dyst), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -84.00 -37.65 -15.47 24.53 228.35
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 67.0249 2.7110 24.724 <2e-16 ***
## par_catSecond 0.4429 3.8446 0.115 0.9083
## par_catThird or more 2.6221 3.2911 0.797 0.4257
## dyst -0.5428 7.3977 -0.073 0.9415
## par_catSecond:dyst -5.1015 14.7724 -0.345 0.7299
## par_catThird or more:dyst 33.8958 13.5848 2.495 0.0127 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 51.51 on 1568 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.006688, Adjusted R-squared: 0.00352
## F-statistic: 2.111 on 5 and 1568 DF, p-value: 0.0615Réponse: Notez que nous avons maintenant 2 coefficients (par_catSecond:dyst et par_catThird or more:dyst) qui, ensemble, représentent l’interaction entre par_cat et dyst. Nous devons donc faire un test de F sur ces 2 coefficients à la fois.
#Le modèle réduit sans les deux coefficients:
modele_red <- lm(data=daisy2_mod,
wpc ~ (par_cat+dyst)
)
#La fonction anova() pour comparer les modèles:
anova(modele6,
modele_red)## Analysis of Variance Table
##
## Model 1: wpc ~ (par_cat * dyst)
## Model 2: wpc ~ (par_cat + dyst)
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 1568 4160082
## 2 1570 4179615 -2 -19533 3.6812 0.02541 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Oui l’interaction est significative, nous obtenons une valeur de P=0.03 pour le test de F.
c. Quel est le nombre de jours moyen jusqu’à la saillie fécondante pour chacune des catégories de parité et de dystocie (i.e. remplir le tableau suivant)? Pour quel niveau de parité les différences semblent les plus importantes?
| Parite | Dystocie_0 | Dystocie_1 |
|---|---|---|
| 1ère lactation | 67.0 jours | 67.0-0.5=66.5 jours |
| 2ième lactation | 67.0+0.4=67.4 jours | 67.0+0.4-0.5-5.1=61.8 jours |
| 3ième ou plus | 67.0+2.6=69.6 jours | 67.0+2.6-0.5+33.9=103.0 jours |
6.11 Travaux pratiques 2 - Régression linéaire - Évaluation du modèle
6.11.1 Exercices
Pour ce TP utilisez le fichier DAISY2 (voir description VER p.809).
Ne sélectionnez que les 7 troupeaux avec h7=1.
Nous nous intéresserons d’abord au modèle suivant qui permet d’évaluer l’effet de dystocie (dyst) sur le nombre de jours jusqu’à la saillie fécondante (WPC). Cette association est ajustée pour 3 facteurs confondants (parity, herd_size et twin). Un des confondants (herd_size) n’a pas une relation linéaire avec WPC. Cette relation a donc dû être modélisée avec l’ajout d’un terme quadratique. Finalement, l’interaction entre dystocie et parité est également d’intérêt.
\(wpc = β_0 +β_1*dyst + β_2*parity + β_3*dyst*parity + β_4*herdsize + β_5*herdsize^2 + β_6*twin\)
1) D’abord vous pourriez créer les nouvelles variables centrées et quadratiques qui seront utilisées dans ce modèle.
\(Parity\) pourrait être centrée sur une première lactation.
\(Herdsize\) pourrait être centré sur 250 vaches.
\(Herdsize^2\) sera, en fait, votre variable herd_size centrée et mise au carré.
Maintenant, estimez ce modèle à l’aide de la fonction lm et évaluez d’abord graphiquement les suppositions de normalité des résiduels (i.e. l’histogramme des résiduels et le Q-Q plot) et d’homoscédasticité de la variance (i.e. les résiduels x valeurs prédites). Quelles sont vos conclusions ? Notez qu’un simple histogramme de WPC vous aurait possiblement aussi indiqué les problèmes potentiels avec la variable WPC.
2) Afin d’améliorer les suppositions du modèle (i.e. normalité des résiduels et homoscédasticité), vous pourriez tenter de transformer WPC. Essayez les transformations suivantes et utilisez les comme variables dépendantes dans votre modèle à la place de WPC. Dans quels cas les suppositions de normalité et d’homoscédasticité sont améliorées et quelle transformation préféreriez-vous utiliser?
- Le log naturel de WPC
- Normalité des résiduels ?
- Homoscédasticité ?
- L’inverse de WPC (1/WPC)
- Normalité des résiduels ?
- Homoscédasticité ?
- La racine carrée de WPC
- Normalité des résiduels ?
- Homoscédasticité ?
3) Outre l’amélioration des suppositions du modèle, est-ce que la transformation par le logarithme naturel pourrait vous offrir d’autres avantages comparativement, par exemple, à la transformation par la racine carrée?
4) Vous décidez donc de continuer à travailler avec le logarithme naturel de WPC. Rappelez-vous que lorsque vous aviez évalué la relation entre herd_size et WPC, cette relation semblait curvilinéaire. Est-ce que cela implique que la relation entre herd_size et le logarithme naturel de WPC est également curvilinéaire ?
5) Évaluez graphiquement et à l’aide de termes quadratique et cubique la relation entre herd_size et le logarithme naturel de WPC. Avez-vous besoin d’inclure un terme au carré ? Un terme au cube ?
6) Dans votre modèle avec le logarithme naturel de WPC, et herd_size modélisé avec les termes polynomiaux appropriés, est-ce que l’interaction entre dyst et parity est toujours statistiquement significative ?
7) Si l’interaction n’est plus statistiquement significative cela signifie que:
- L’effet de dystocie ne varie pas en fonction de la parité
- Le terme d’interaction n’est pas nécessaire dans le modèle
- Le coefficient de régression pour le terme d’interaction n’est pas différent de zéro
- Toutes ces réponses
8) Comme vous avez pu le noter, transformer la variable dépendante vous oblige à revoir pratiquement tout votre modèle de A à Z. Mais bon, votre modèle final pourrait donc être :
\(log(wpc) = β_0 +β_1*dyst + β_2*parity_c + β_3*herdsize _c + β_4*herdsize_c^2 + β_5*twin\)
Évaluez une dernière fois les suppositions de normalité des résiduels et d’homoscédasticité (puisque vous ne l’avez pas encore fait pour ce modèle sans l’interaction \(dyst*parity\)) et calculez dans une nouvelle table les valeurs prédites, les résiduels de Student, les leviers et les distances de Cook.
Combien d’observations ont des résiduels larges (résiduels de Student > 3.0 ou < -3.0)? Ont-elles quelque chose en commun en ce qui a trait à leurs valeurs de WPC, dyst, parity, herd_size ou twin?
Vous pourriez représenter graphiquement les résiduels de Student en fonction de WPC pour mieux visualiser où se situent ses résiduels larges. Quel genre d’observations (en termes de WPC) le modèle semble avoir de la difficulté à prédire?
Évaluez maintenant les 5 ou 10 observations avec les leviers les plus élevés. Encore une fois, ont-elles quelque chose en commun?
Les observations avec des résiduels ou des leviers larges (ou les deux) sont des observations qui peuvent potentiellement influencer le modèle de régression. Les distances de Cook nous permettront d’identifier quelles observations avaient effectivement une influence sur le modèle. Évaluez donc maintenant les 5 ou 10 observations avec les distances de Cook les plus élevées. Ont-elles quelque chose en commun ?
Vérifiez maintenant jusqu’à quel point ces observations influencent vos résultats en calculant de nouveau votre modèle mais sans les observations avec les distance de Cook les plus élevées (e.g. les 7 observations avec les distances de Cook > 0.010). Est-ce que les conclusions des tests de F ou de T changent comparativement au modèle calculé au début de la question 8? Est-ce que les estimés obtenus changent beaucoup ? Pour quel paramètre l’estimé semble être le plus affecté ? Est-ce en accord avec votre réponse à la question 8.d. ?
6.11.2 Code R et réponses
1) D’abord vous pourriez créer les nouvelles variables centrées et quadratiques qui seront utilisées dans ce modèle. Maintenant, estimez ce modèle à l’aide de la fonction lm et évaluez d’abord graphiquement les suppositions de normalité des résiduels (i.e. l’histogramme des résiduels et le Q-Q plot) et d’homoscédasticité de la variance (i.e. les résiduels x valeurs prédites). Quelles sont vos conclusions? Notez qu’un simple histogramme de WPC vous aurait possiblement aussi indiqué les problèmes potentiels avec la variable WPC.
#Ouvrir le jeu de données
daisy2 <-read.csv(file="daisy2.csv",
header=TRUE,
sep=",")
daisy2_mod<-subset(daisy2,
h7==1)
#Nous génèrons les nouvelles variables
daisy2_mod$par_ct <- daisy2_mod$parity-1
daisy2_mod$herd_size_ct <- daisy2_mod$herd_size-250
daisy2_mod$herd_size_ct_sq <-daisy2_mod$herd_size_ct*daisy2_mod$herd_size_ct
#Le modèle
modele1<-lm(data=daisy2_mod,
wpc ~ (dyst*par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
plot(modele1, 2) #Nous demandons la 2e figure Normal Q-Q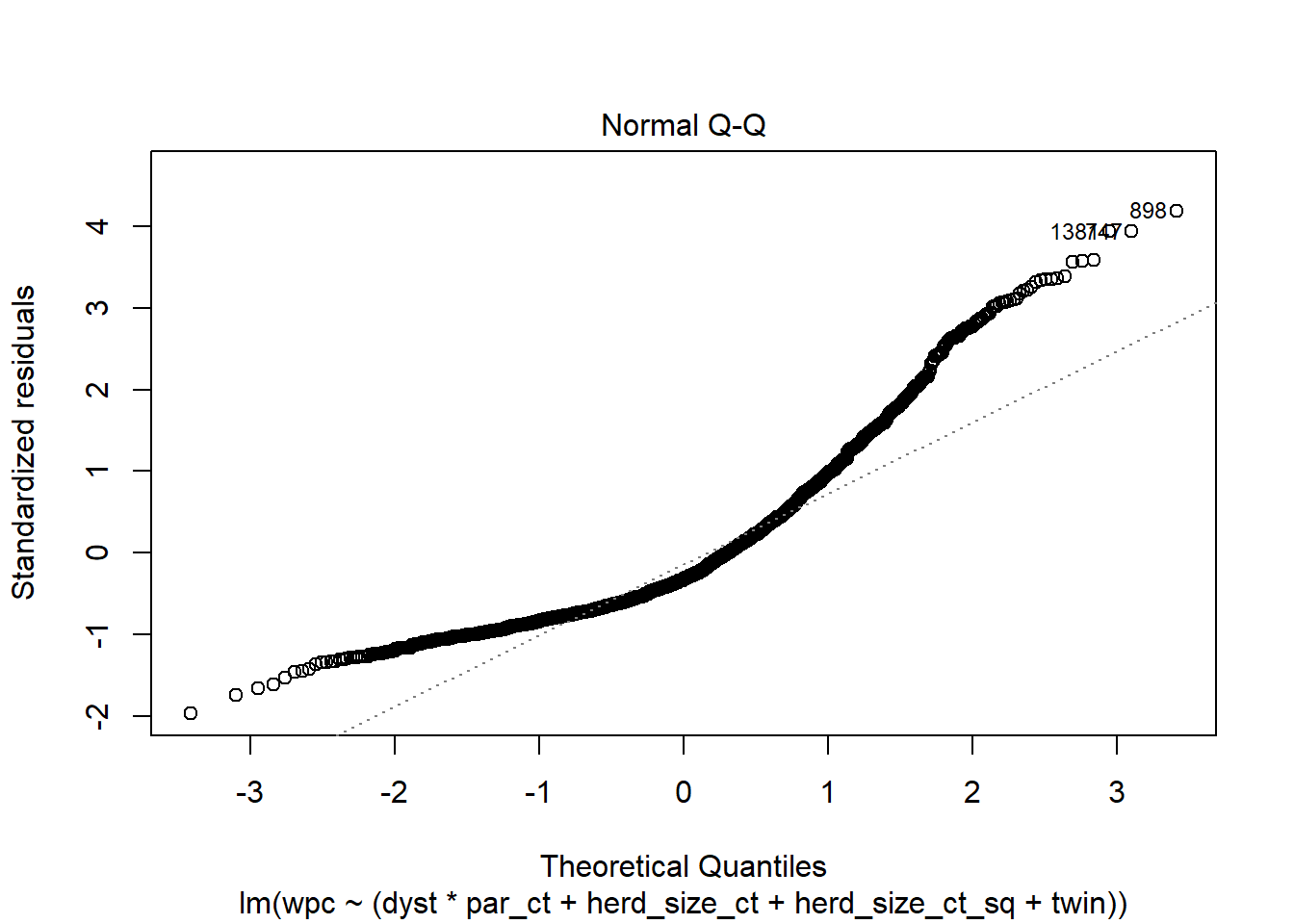
Figure 6.9: Graphique Q-Q des résiduels.
Réponse: La normalité des résiduels est problématique
plot(modele1, 1) #Nous demandons la figure Residual vs Fitted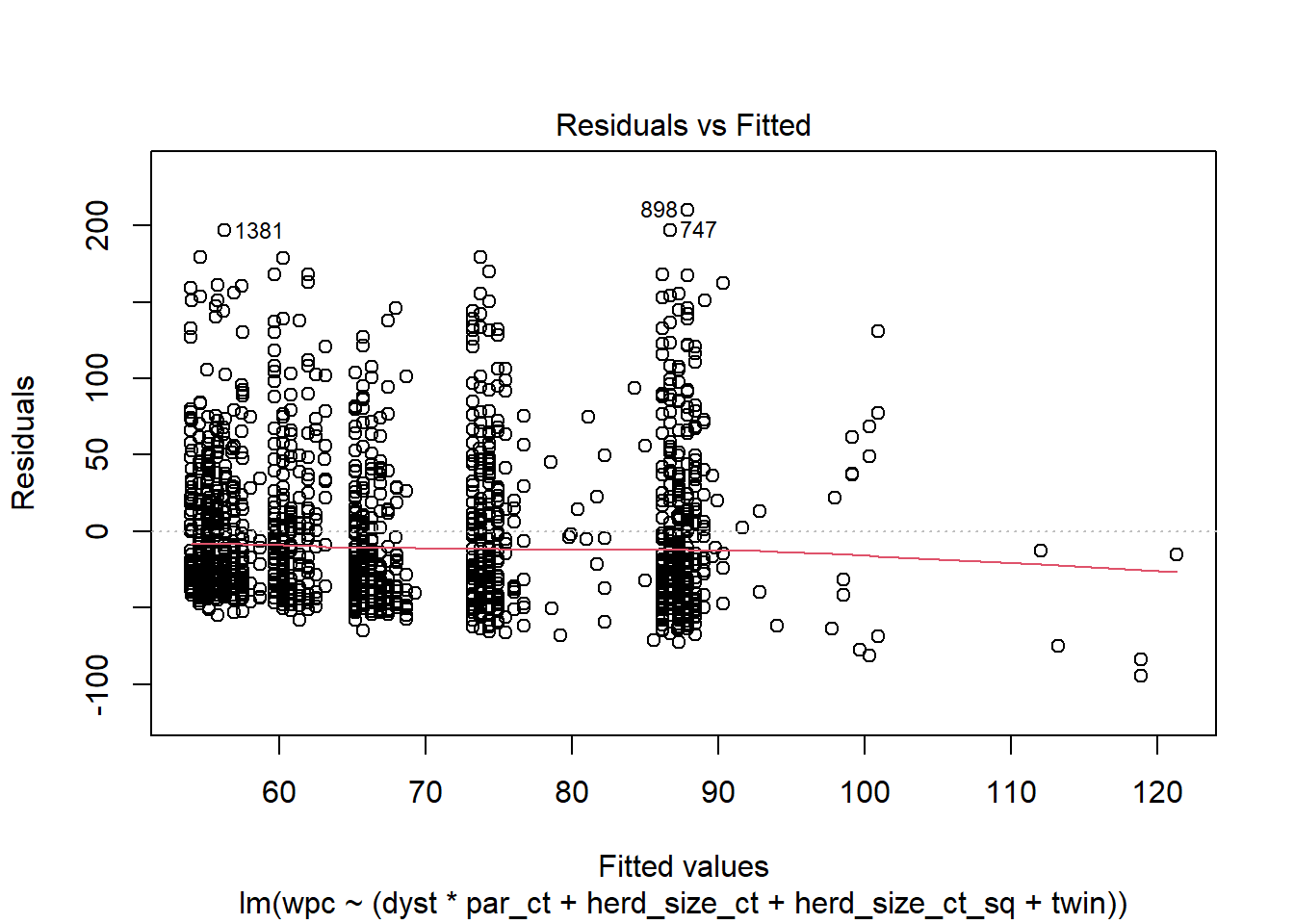
Figure 6.10: Graphique des résiduels x valeurs prédites.
Réponse: Il semble aussi y avoir un problème d’hétéroscédascticité (i.e. la variance augmente avec l’augmentation des valeurs prédites).
2) Afin d’améliorer les suppositions du modèle (i.e. normalité des résiduels et homoscédasticité), vous pourriez tenter de transformer WPC. Essayez les transformations suivantes et utilisez les comme variables dépendantes dans votre modèle à la place de WPC. Dans quels cas les suppositions de normalité et d’homoscédasticité sont améliorées et quelle transformation préféreriez-vous utiliser?
#Nous créons les nouvelles variables en bloc:
daisy2_mod$ln_wpc <- log(daisy2_mod$wpc)
daisy2_mod$inv_wpc <- 1/daisy2_mod$wpc
daisy2_mod$sqr_wpc <- sqrt(daisy2_mod$wpc)- Le log naturel de WPC
- Normalité des résiduels ?
- Homoscédasticité ?
#Le modèle pour log_wpc
modele_log<-lm(data=daisy2_mod,
ln_wpc ~ (dyst*par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
plot(modele_log, 1) #La figure Residual vs Fitted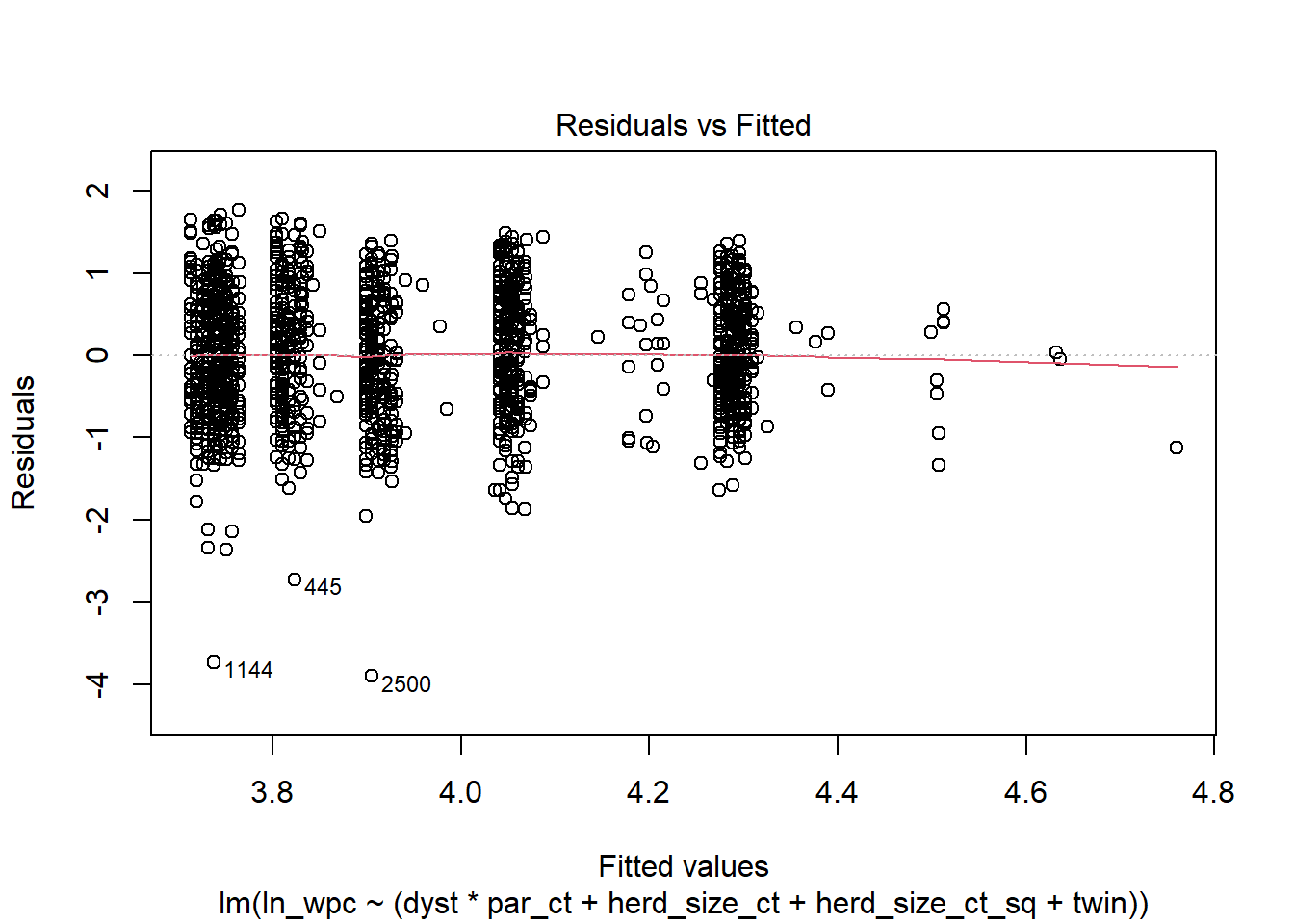
Figure 6.11: Graphique des résiduels x valeurs prédites.
plot(modele_log, 2) #La figure Normal Q-Q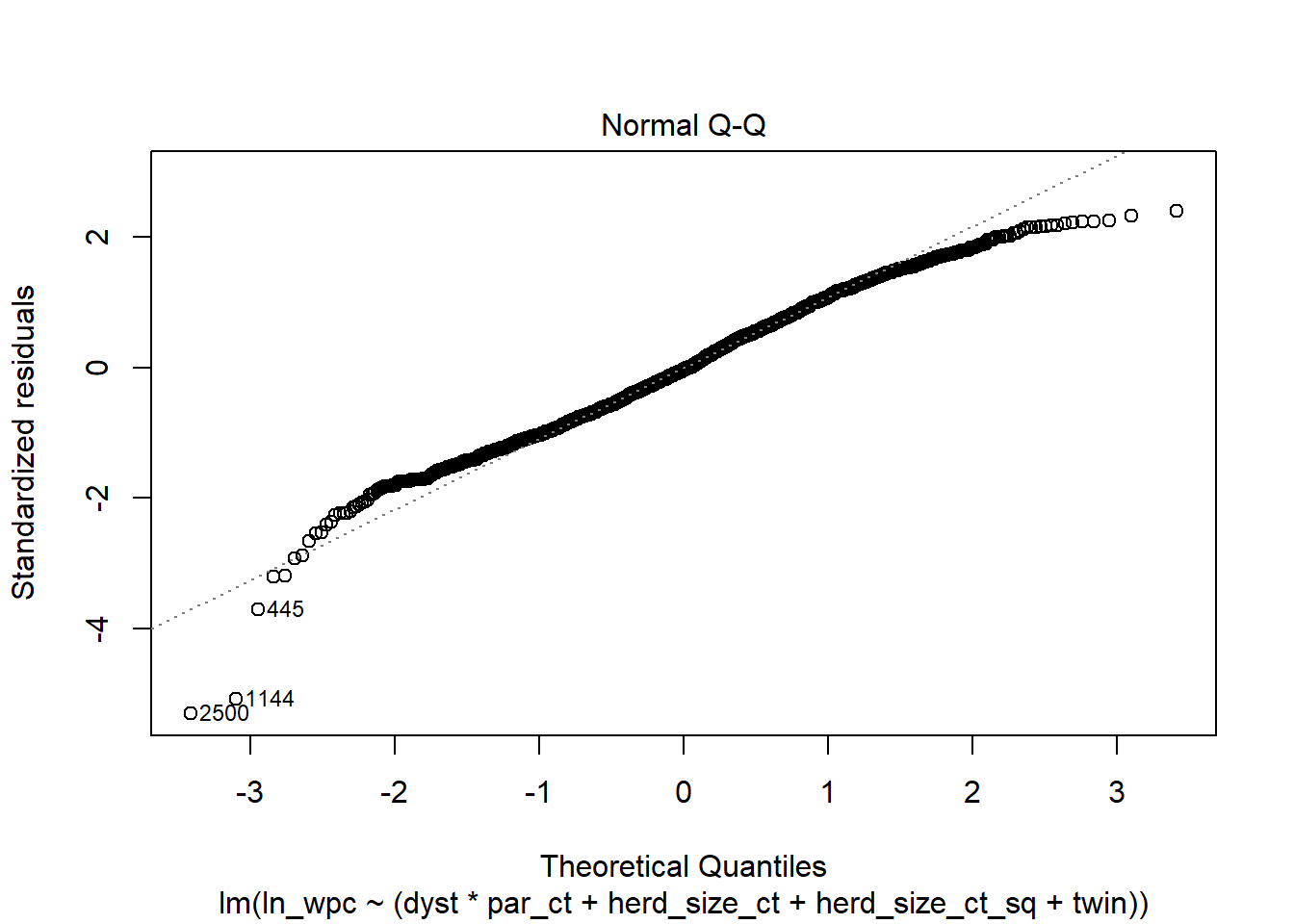
Figure 6.12: Graphique Q-Q des résiduels.
Réponse: Normalité est très améliorée; homoscédasticité est beaucoup mieux. Peut-être une légère diminution de la variance avec augmentation des valeurs prédites.
- L’inverse de WPC (1/WPC)
- Normalité des résiduels ?
- Homoscédasticité ?
#Le modèle pour inv_wpc
modele_inv<-lm(data=daisy2_mod,
inv_wpc ~ (dyst*par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
plot(modele_inv, 1) #La figure Residual vs Fitted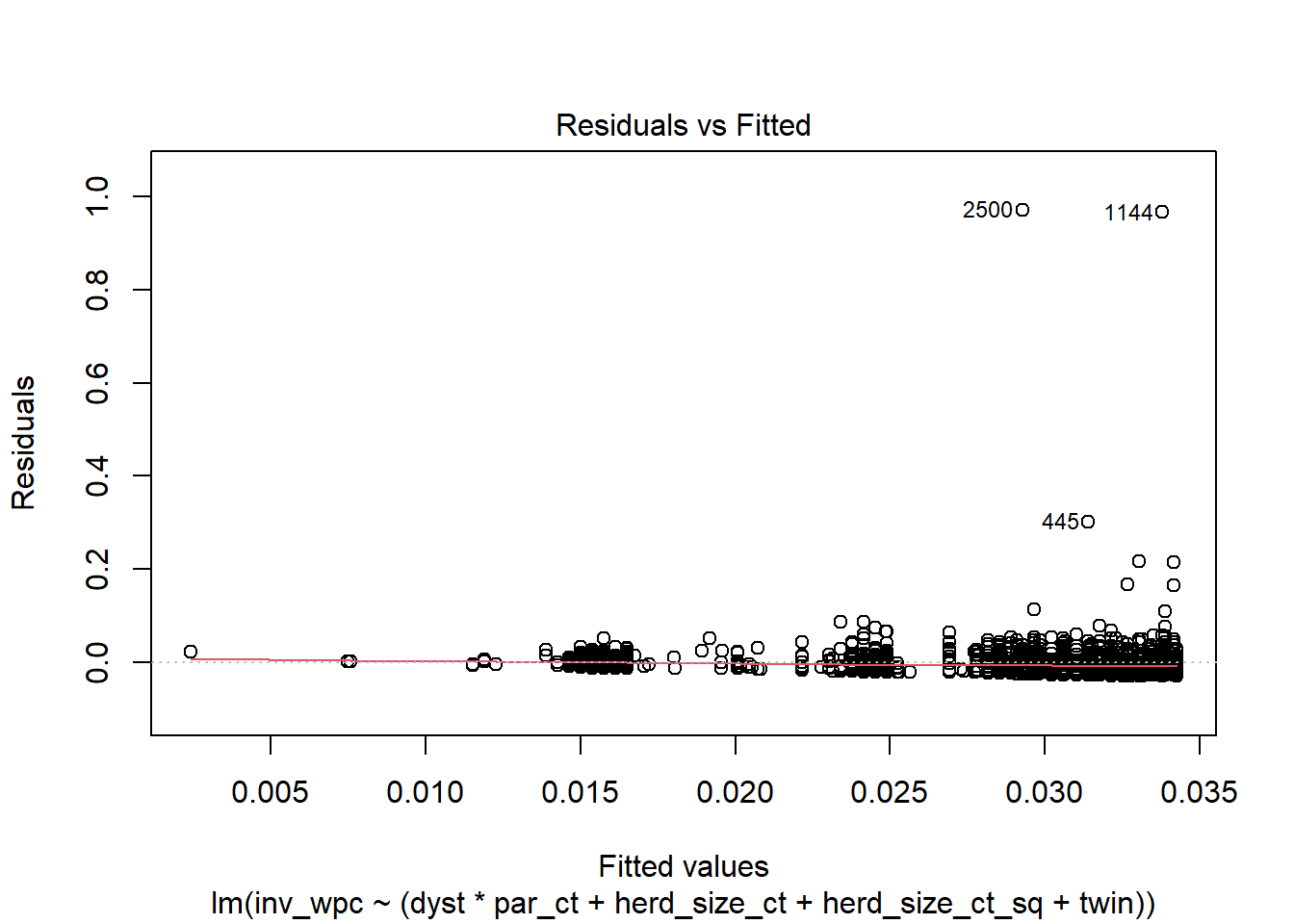
Figure 6.13: Graphique des résiduels x valeurs prédites.
plot(modele_inv, 2) #La 2 figure Normal Q-Q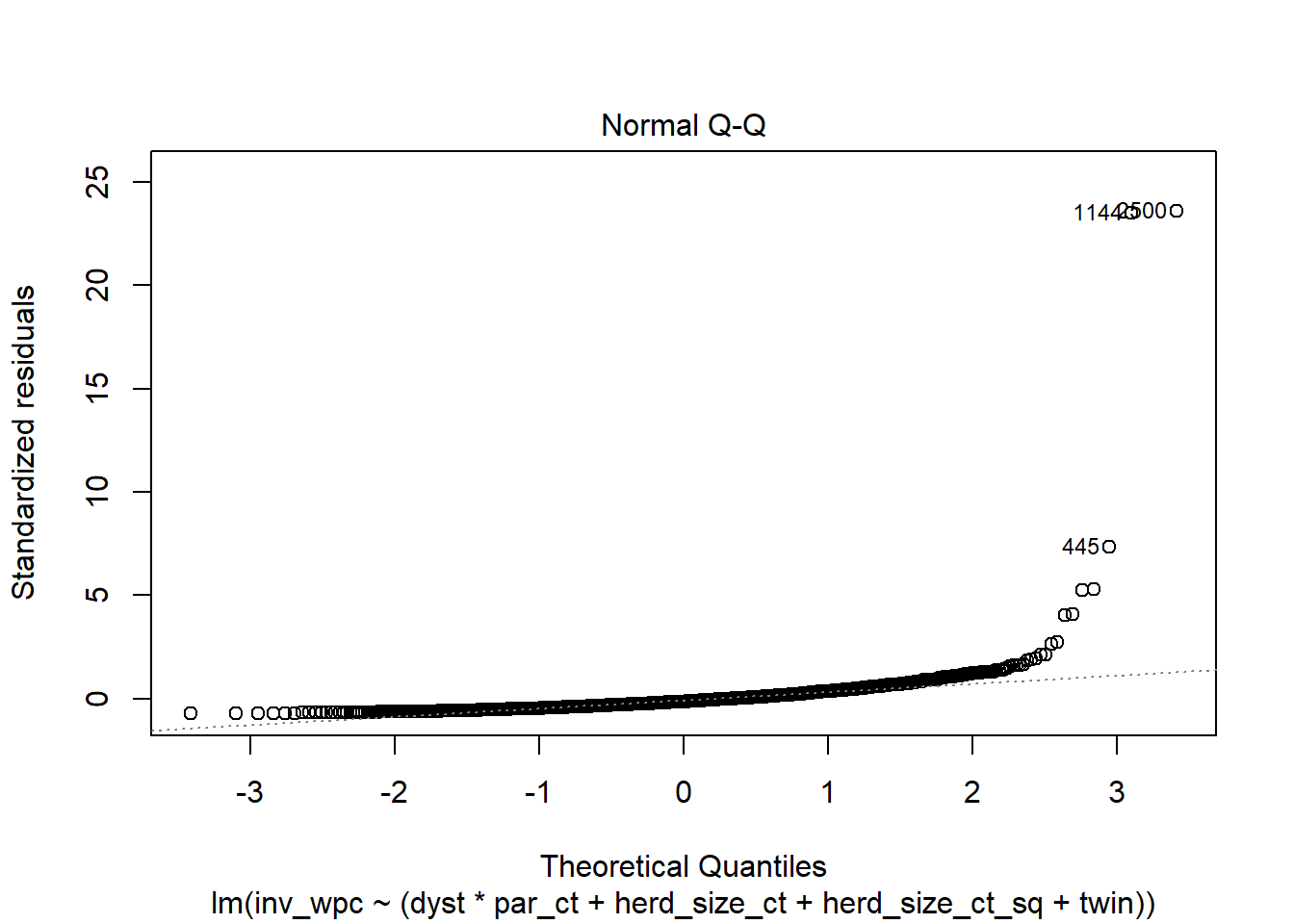
Figure 6.14: Graphique Q-Q des résiduels.
Réponse: Normalité est pire; homoscédasticité est pire aussi, variance augmente clairement avec augmentation des valeurs prédites.
- La racine carrée de WPC
- Normalité des résiduels ?
- Homoscédasticité ?
#Le modèle pour sqr_wpc
modele_sqr<-lm(data=daisy2_mod,
sqr_wpc ~ (dyst*par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
plot(modele_sqr, 1) #La figure Residual vs Fitted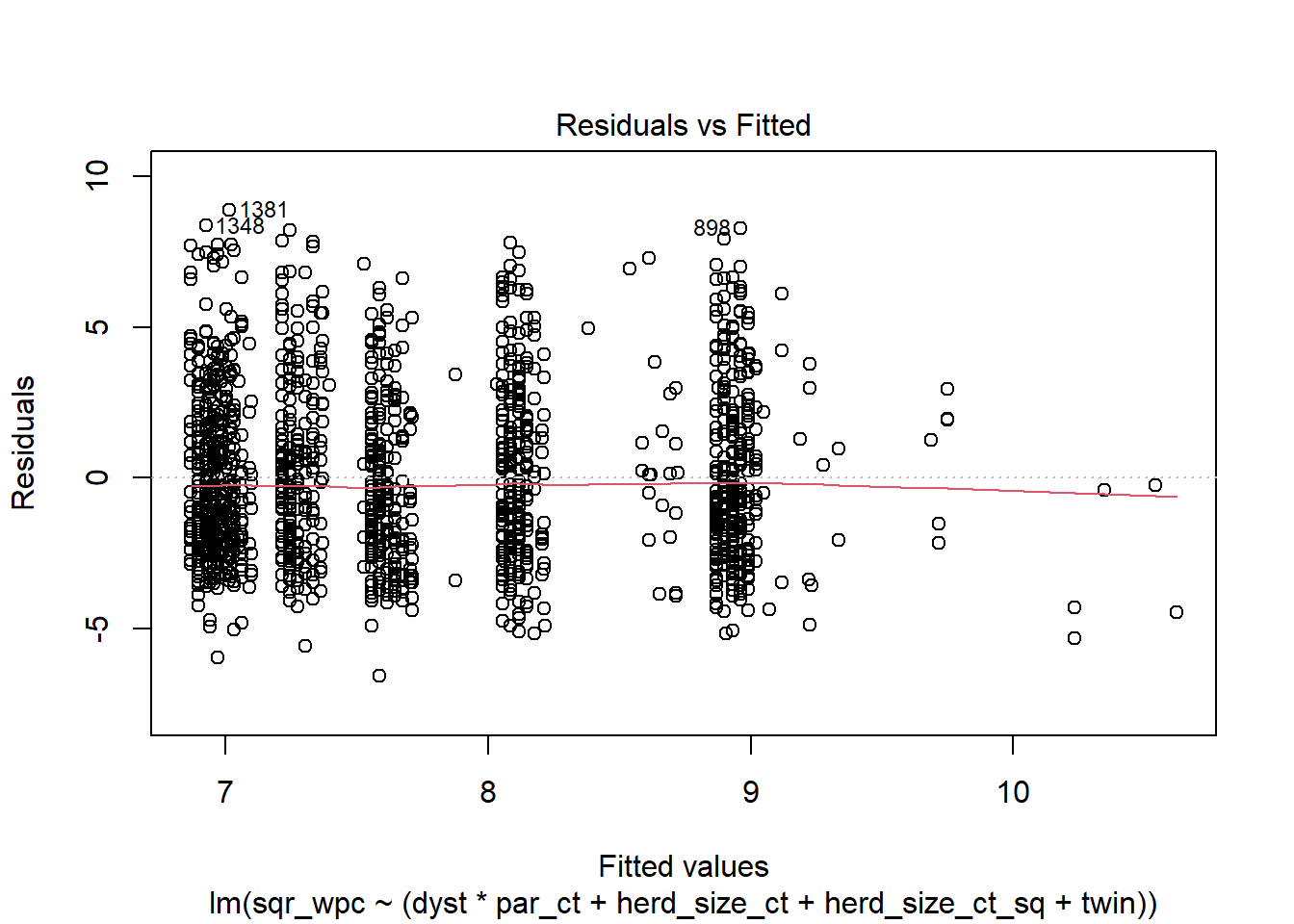
Figure 6.15: Graphique des résiduels x valeurs prédites.
plot(modele_sqr, 2) #La figure Normal Q-Q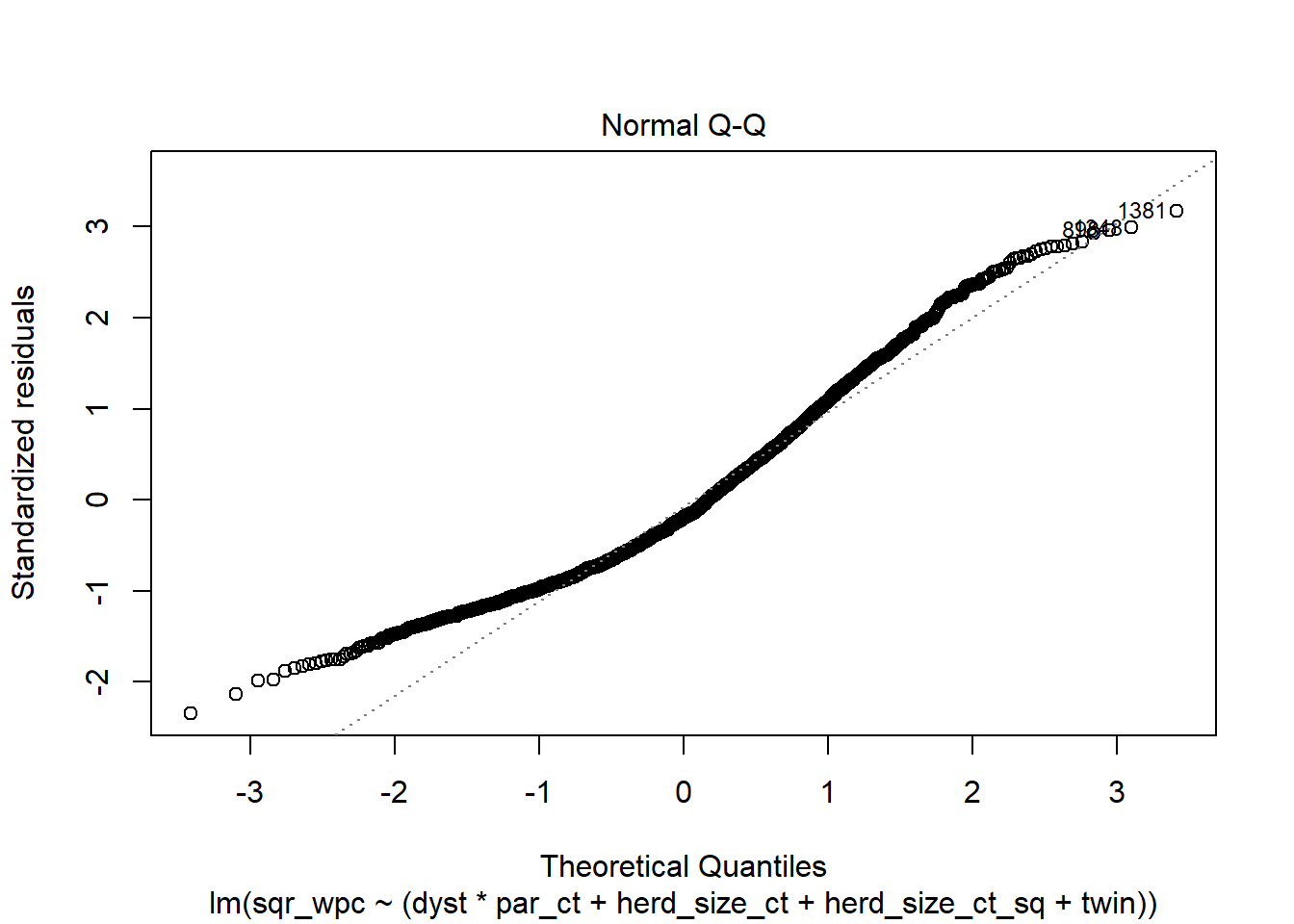
Figure 6.16: Graphique Q-Q des résiduels.
Réponse: Normalité des résiduels est un peu mieux que WPC, mais encore problématique (ln_wpc était meilleur de ce côté). L’homoscédasticité est beaucoup mieux. Peut-être même un peu mieux que ln_wpc sur cet aspect.
3) Outre l’amélioration des suppositions du modèle, est-ce que la transformation par le logarithme naturel pourrait vous offrir d’autres avantages comparativement, par exemple, à la transformation par la racine carrée?
Réponse: Oui, côté interprétation ce sera plus facile parce que nous pourrons directement retransformer et plus facilement interpréter l’estimé (i.e. l’exposant de \(β_1\)) et son IC 95%. Par exemple, avec le \(β\) de dyst (et IC 95%) de 0.027 (-0.163, 0.218) nous obtiendrons des valeurs retransformées de 1.03 (0.85, 1.24). Nous pourrons interpréter ces valeurs comme suit : WPC est multiplié par un facteur de 1.03 lorsque dystocie est présente, et nous avons 95% de certitude que la vraie valeur se situe entre une multiplication par 0.85 (i.e. une diminution du nombre de jours) et une multiplication par 1.24.
4) Vous décidez donc de continuer à travailler avec le logarithme naturel de WPC. Rappelez-vous que lorsque vous aviez évalué la relation entre herd_size et WPC, cette relation semblait curvilinéaire. Est-ce que cela implique que la relation entre herd_size et le logarithme naturel de WPC est également curvilinéaire ?
Réponse: Pas nécessairement, ln_wpc est une variable différente.
5) Évaluez graphiquement et à l’aide de termes quadratique et cubique la relation entre herd_size et le logarithme naturel de WPC. Avez-vous besoin d’inclure un terme au carré ? Un terme au cube ?
library(ggplot2)
ggplot(daisy2_mod,
aes(herd_size, ln_wpc)
) +
geom_point() +
geom_smooth(method="loess",
span=2) +
theme_bw() 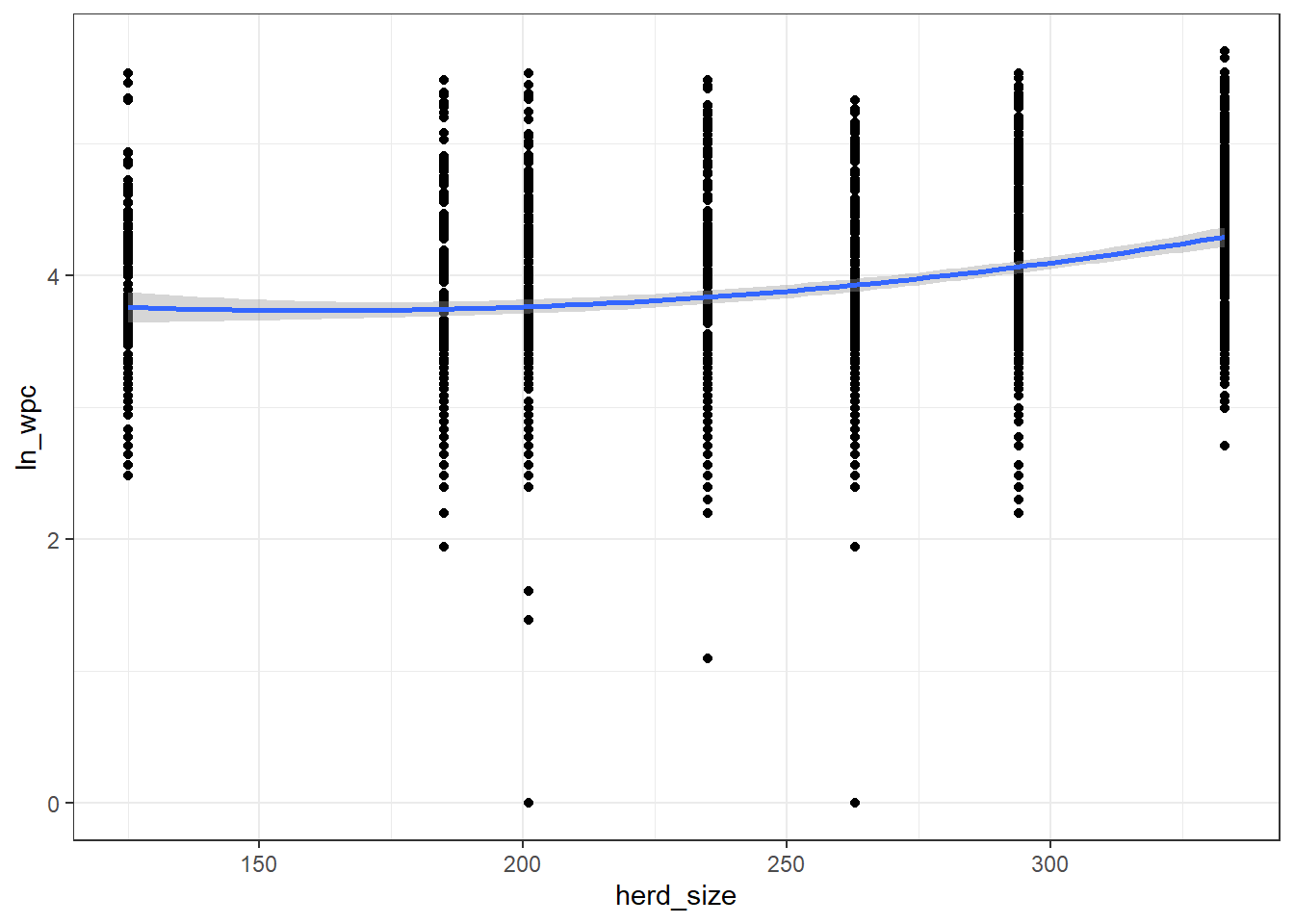
Figure 6.17: Relation entre la taille du troupeau (herd_size) et le nombre de jours jusqu’à la saillie fécondante (wpc) avec courbe lissée avec un facteur de 2.
Réponse: Graphiquement, la relation avec ln_wpc semble aussi curvilinéaire.
#Le modèle avec le terme au carré
modele_log2 <- lm(data=daisy2_mod,
ln_wpc ~ (herd_size_ct + herd_size_ct_sq)
)
summary(modele_log2)##
## Call:
## lm(formula = ln_wpc ~ (herd_size_ct + herd_size_ct_sq), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.9279 -0.5420 -0.0283 0.5442 1.7717
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.881e+00 2.568e-02 151.147 < 2e-16 ***
## herd_size_ct 3.357e-03 3.145e-04 10.676 < 2e-16 ***
## herd_size_ct_sq 1.922e-05 4.564e-06 4.212 2.68e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7402 on 1571 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.06839, Adjusted R-squared: 0.06721
## F-statistic: 57.67 on 2 and 1571 DF, p-value: < 2.2e-16Réponse: Le terme au carré est significatif (P < 0.001), cela confirme la relation curvilinéaire.
#La variable au cube
daisy2_mod$herd_size_ct_cu <-daisy2_mod$herd_size_ct*daisy2_mod$herd_size_ct*daisy2_mod$herd_size_ct
#Le modèle avec le terme au cube
modele_log3<-lm(data=daisy2_mod,
ln_wpc ~ (herd_size_ct + herd_size_ct_sq + herd_size_ct_cu)
)
summary(modele_log3)##
## Call:
## lm(formula = ln_wpc ~ (herd_size_ct + herd_size_ct_sq + herd_size_ct_cu),
## data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.9243 -0.5377 -0.0293 0.5416 1.7768
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.879e+00 2.754e-02 140.868 < 2e-16 ***
## herd_size_ct 3.230e-03 6.862e-04 4.707 2.73e-06 ***
## herd_size_ct_sq 2.012e-05 6.254e-06 3.217 0.00132 **
## herd_size_ct_cu 1.687e-08 8.074e-08 0.209 0.83452
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7404 on 1570 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.06842, Adjusted R-squared: 0.06664
## F-statistic: 38.44 on 3 and 1570 DF, p-value: < 2.2e-16Réponse: Par contre le terme au cube n’est pas nécessaire (P=0.83) je pourrais l’enlever du modèle.
6) Dans votre modèle avec le logarithme naturel de WPC, et herd_size modélisé avec les termes polynomiaux appropriés, est-ce que l’interaction entre dyst et parity est toujours statistiquement significative ?
#Le modèle pour log_wpc
modele_log<-lm(data=daisy2_mod,
ln_wpc ~ (dyst*par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
summary(modele_log)##
## Call:
## lm(formula = ln_wpc ~ (dyst * par_ct + herd_size_ct + herd_size_ct_sq +
## twin), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.9054 -0.5348 -0.0242 0.5413 1.7691
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.851e+00 3.446e-02 111.734 < 2e-16 ***
## dyst 2.747e-02 9.715e-02 0.283 0.77735
## par_ct 6.599e-03 1.292e-02 0.511 0.60960
## herd_size_ct 3.438e-03 3.163e-04 10.872 < 2e-16 ***
## herd_size_ct_sq 2.029e-05 4.580e-06 4.430 1.01e-05 ***
## twin 4.577e-01 1.438e-01 3.184 0.00148 **
## dyst:par_ct 1.031e-01 6.160e-02 1.673 0.09449 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7373 on 1567 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.07782, Adjusted R-squared: 0.07429
## F-statistic: 22.04 on 6 and 1567 DF, p-value: < 2.2e-16Réponse: Non, P =0.0945
7) Si l’interaction n’est plus statistiquement significative cela signifie que:
- L’effet de dystocie ne varie pas en fonction de la parité
- Le terme d’interaction n’est pas nécessaire dans le modèle
- Le coefficient de régression pour le terme d’interaction n’est pas différent de zéro
- Toutes ces réponses
Réponse: d. Toutes ces réponses.
8) Comme vous avez pu le noter, transformer la variable dépendante vous oblige à revoir pratiquement tout votre modèle de A à Z. Mais bon, votre modèle final pourrait donc être :
\(log(wpc) = β_0 +β_1*dyst + β_2*parity_c + β_3*herdsize _c + β_4*herdsize_c^2 + β_5*twin\)
Évaluez une dernière fois les suppositions de normalité des résiduels et d’homoscédasticité (puisque vous ne l’avez pas encore fait pour ce modèle sans l’interaction \(dyst*parity\)) et calculez dans une nouvelle table les valeurs prédites, les résiduels de Student, les leviers et les distances de Cook.
#Générons le modèle sans l'interaction
modele_final<-lm(data=daisy2_mod,
ln_wpc ~ (dyst + par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
summary(modele_final)##
## Call:
## lm(formula = ln_wpc ~ (dyst + par_ct + herd_size_ct + herd_size_ct_sq +
## twin), data = daisy2_mod)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.9017 -0.5355 -0.0242 0.5342 1.7585
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.842e+00 3.413e-02 112.583 < 2e-16 ***
## dyst 1.196e-01 8.008e-02 1.494 0.13548
## par_ct 1.112e-02 1.264e-02 0.880 0.37911
## herd_size_ct 3.440e-03 3.164e-04 10.870 < 2e-16 ***
## herd_size_ct_sq 2.035e-05 4.582e-06 4.441 9.58e-06 ***
## twin 4.523e-01 1.438e-01 3.145 0.00169 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7378 on 1568 degrees of freedom
## (402 observations effacées parce que manquantes)
## Multiple R-squared: 0.07617, Adjusted R-squared: 0.07323
## F-statistic: 25.86 on 5 and 1568 DF, p-value: < 2.2e-16#Vérifions d'abord les suppositions:
plot(modele_final, 2)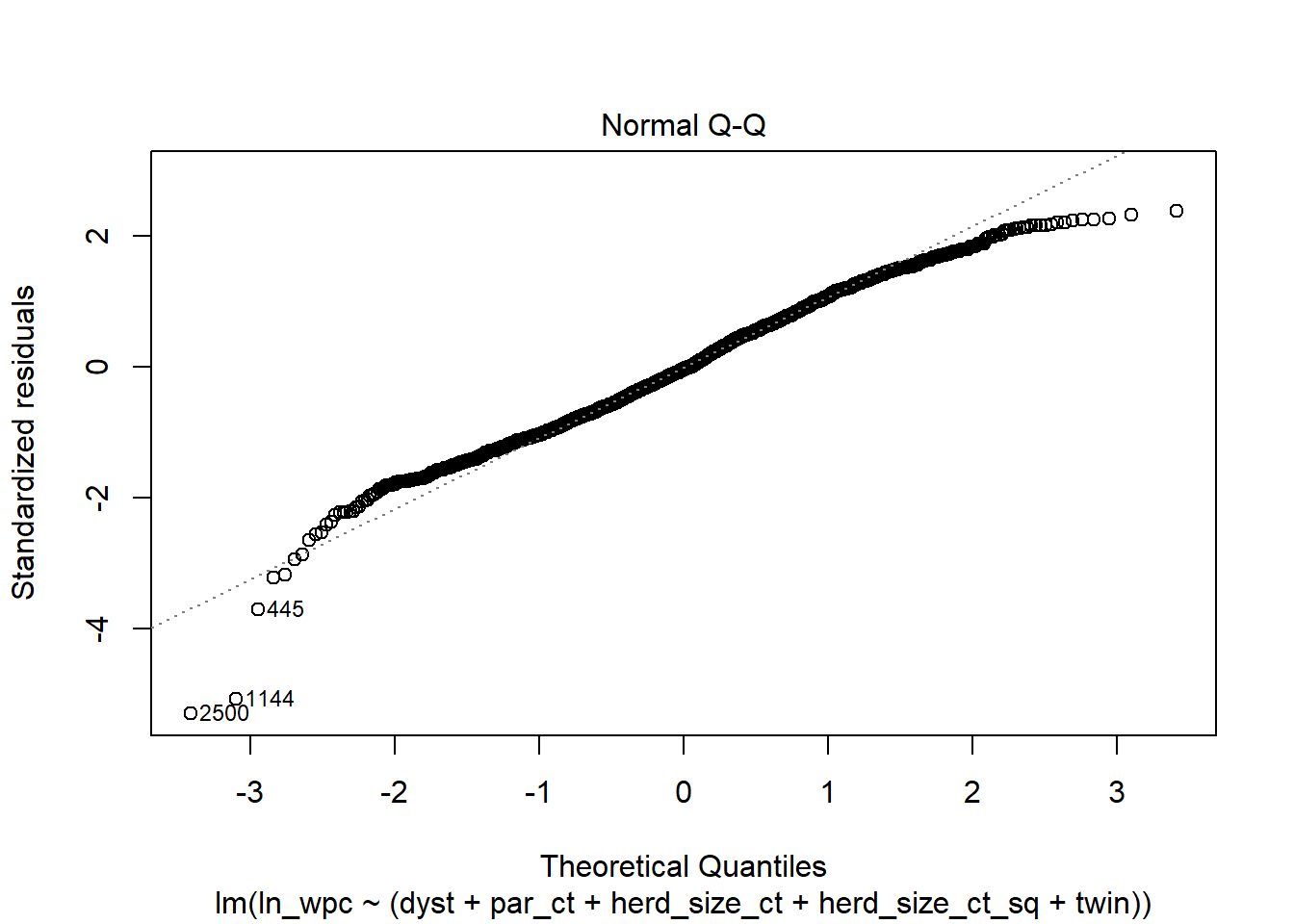
Figure 6.18: Graphique des résiduels x valeurs prédites.
plot(modele_final, 1)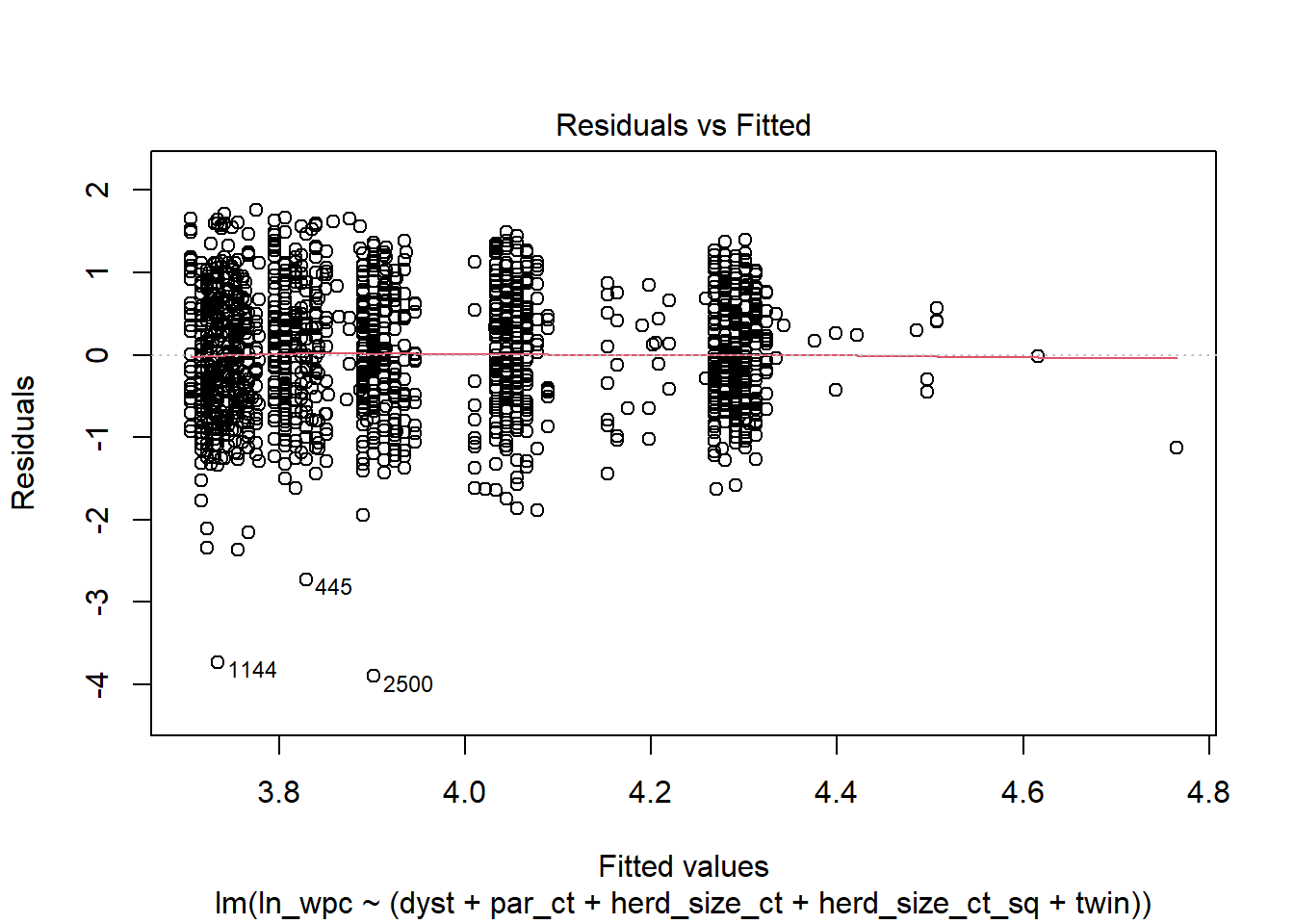
Figure 6.19: Graphique Q-Q des résiduels.
Réponses: OK, les suppositions semblent respectées.
#Enregistrons les valeurs prédites, les résiduels de Student, les leviers et les distance de Cook
library(broom)
diag <- augment(modele_final) #Nous venons de créer un nouveau jeu de données dans lequel les résiduels, les distances de cook, etc se trouvent maintenant- Combien d’observations ont des résiduels larges (résiduels de Student > 3.0 ou < -3.0)? Ont-elles quelque chose en commun en ce qui a trait à leurs valeurs de WPC, dyst, parity, herd_size ou twin?
#Nous pouvons filtrer cette table pour ne conserver que les résiduels standardisés larges
diag_res <- subset(diag, (.std.resid >=3.0 | .std.resid<=-3.0))
diag_res## # A tibble: 5 × 13
## .rownames ln_wpc dyst par_ct herd_size…¹ herd_…² twin .fitted .resid .hat
## <chr> <dbl> <int> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 445 1.10 0 3 -15 225 0 3.83 -2.73 0.00189
## 2 1091 1.39 0 3 -49 2401 0 3.76 -2.37 0.00190
## 3 1144 0 0 1 -49 2401 0 3.73 -3.73 0.00153
## 4 1177 1.39 0 0 -49 2401 0 3.72 -2.34 0.00223
## 5 2500 0 0 1 13 169 0 3.90 -3.90 0.00134
## # … with 3 more variables: .sigma <dbl>, .cooksd <dbl>, .std.resid <dbl>, and
## # abbreviated variable names ¹herd_size_ct, ²herd_size_ct_sqRéponse: 5 observations ont des résiduels larges. Elles ont toutes des WPC très courts (i.e. des log_wpc près de 0 ou 1), pas de jumeaux (twin=0) et pas de dystocie (dyst=0).
- Vous pourriez représenter graphiquement les résiduels de Student en fonction de WPC pour mieux visualiser où se situent ses résiduels larges. Quel genre d’observations (en termes de WPC) le modèle semble avoir de la difficulté à prédire?
library(ggplot2)
ggplot(data=diag, aes(ln_wpc, .std.resid, colour=.std.resid)) +
geom_point() +
theme_bw()+
geom_hline (aes(yintercept=3)) +
geom_hline (aes(yintercept=-3))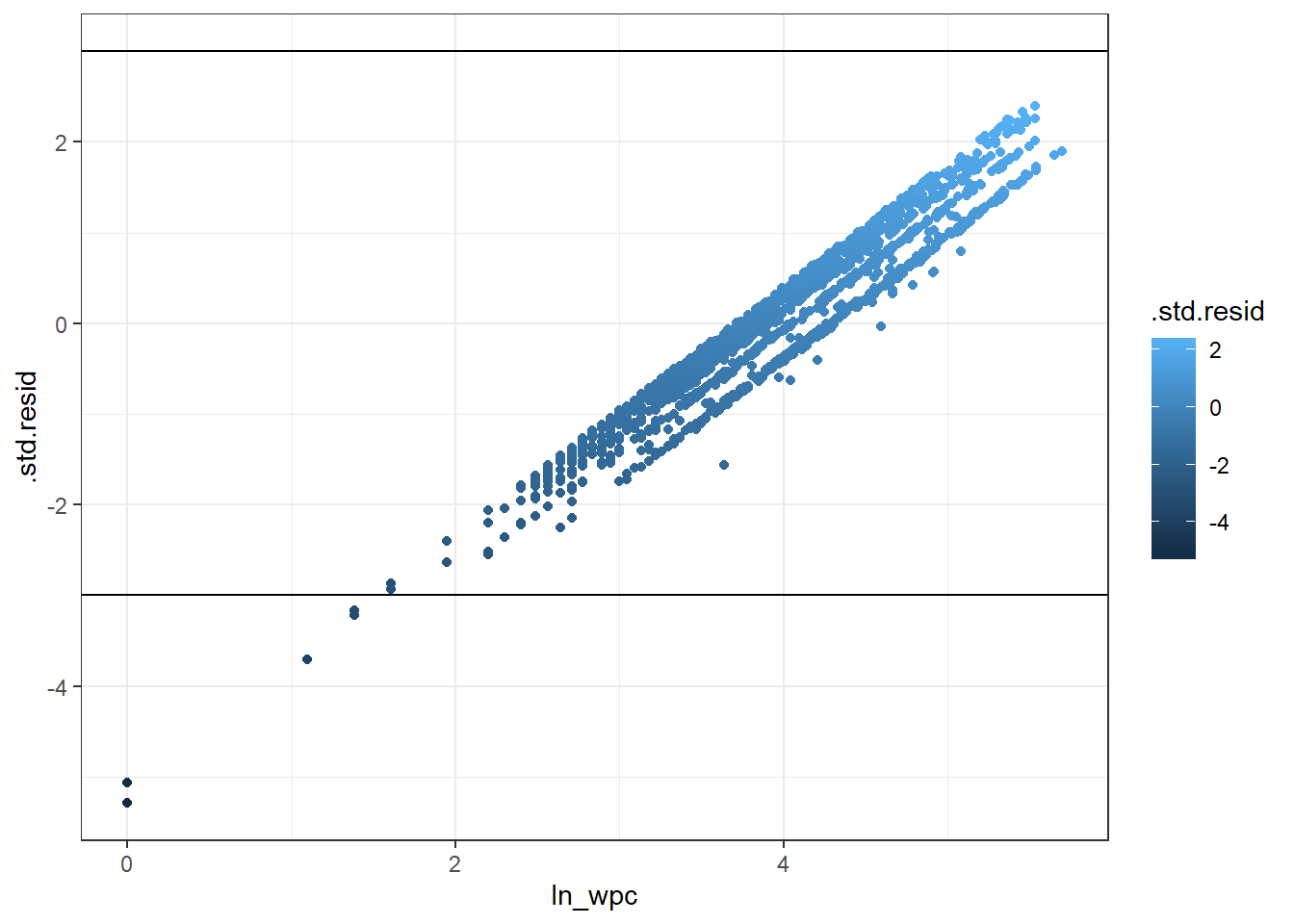
Figure 6.20: Relation entre résiduels standardisés et le nombre de jours jusqu’à la saillie fécondante (wpc) avec courbe lissée avec un facteur de 2.
Réponse: Le modèle semble avoir de la difficulté à prédire les vaches avec log_WPC très court.
- Évaluez maintenant les 5 ou 10 observations avec les leviers les plus élevés. Encore une fois, ont-elles quelque chose en commun?
#Nous pouvons ordonner cette table pour voir les 10 observations avec les leviers les plus larges
diag_hat <- diag[order(-diag$.hat),]
head(diag_hat, 10)## # A tibble: 10 × 13
## .rownames ln_wpc dyst par_ct herd_siz…¹ herd_…² twin .fitted .resid .hat
## <chr> <dbl> <int> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 48 4.60 1 1 44 1936 1 4.62 -0.0211 0.0473
## 2 5628 3.14 1 0 -65 4225 1 4.28 -1.14 0.0470
## 3 1148 3.47 1 1 -49 2401 1 4.31 -0.840 0.0461
## 4 1363 4.36 0 2 -125 15625 1 4.20 0.152 0.0439
## 5 791 3.64 0 4 83 6889 1 4.76 -1.13 0.0405
## 6 313 4.79 0 0 44 1936 1 4.49 0.302 0.0395
## 7 377 5.15 0 5 -15 225 1 4.30 0.844 0.0393
## 8 2627 3.97 0 5 13 169 1 4.40 -0.428 0.0393
## 9 2628 4.66 0 5 13 169 1 4.40 0.265 0.0393
## 10 2513 4.70 0 0 13 169 1 4.34 0.358 0.0392
## # … with 3 more variables: .sigma <dbl>, .cooksd <dbl>, .std.resid <dbl>, and
## # abbreviated variable names ¹herd_size_ct, ²herd_size_ct_sqRéponse: Ces vaches ont toutes eu des jumeaux.
- Les observations avec des résiduels ou des leviers larges (ou les deux) sont des observations qui peuvent potentiellement influencer le modèle de régression. Les distances de Cook nous permettront d’identifier quelles observations avaient effectivement une influence sur le modèle. Évaluez donc maintenant les 5 ou 10 observations avec les distances de Cook les plus élevées. Ont-elles quelque chose en commun ?
#Nous pouvons ordonner cette table pour voir les 10 observations avec les distances de Cook les plus larges
diag_cook <- diag[order(-diag$.cooksd),]
head(diag_cook, 10)## # A tibble: 10 × 13
## .rownames ln_wpc dyst par_ct herd_size…¹ herd_…² twin .fitted .resid .hat
## <chr> <dbl> <int> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 491 2.64 0 2 -15 225 1 4.27 -1.63 0.0375
## 2 5628 3.14 1 0 -65 4225 1 4.28 -1.14 0.0470
## 3 791 3.64 0 4 83 6889 1 4.76 -1.13 0.0405
## 4 1148 3.47 1 1 -49 2401 1 4.31 -0.840 0.0461
## 5 1239 5.45 1 4 -49 2401 0 3.89 1.56 0.0138
## 6 1230 5.53 1 3 -49 2401 0 3.88 1.66 0.0122
## 7 5527 5.48 1 3 -65 4225 0 3.86 1.62 0.0124
## 8 377 5.15 0 5 -15 225 1 4.30 0.844 0.0393
## 9 2543 2.40 1 0 13 169 0 4.01 -1.61 0.0112
## 10 2753 2.40 1 1 13 169 0 4.02 -1.62 0.0111
## # … with 3 more variables: .sigma <dbl>, .cooksd <dbl>, .std.resid <dbl>, and
## # abbreviated variable names ¹herd_size_ct, ²herd_size_ct_sqRéponse: Les vaches qui ont eu des jumeaux sont les pires. Les log_WPC courts (i.e. résiduels larges) ne semblent pas influencer beaucoup le modèle.
- Vérifiez maintenant jusqu’à quel point ces observations influencent vos résultats en calculant de nouveau votre modèle mais sans les observations avec les distance de Cook les plus élevées (e.g. les 7 observations avec les distances de Cook > 0.010).
#Nous générons un jeu de données sans les 7 observations avec les distances de Cook les plus grandes
outlier <- subset(diag, .cooksd<0.01)
#Le modèle sur ce jeu de données réduit
modele_outlier<-lm(data=outlier,
ln_wpc ~ (dyst + par_ct + herd_size_ct + herd_size_ct_sq + twin)
)
summary(modele_outlier)##
## Call:
## lm(formula = ln_wpc ~ (dyst + par_ct + herd_size_ct + herd_size_ct_sq +
## twin), data = outlier)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.9025 -0.5359 -0.0304 0.5329 1.7697
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.847e+00 3.397e-02 113.257 < 2e-16 ***
## dyst 8.378e-02 8.160e-02 1.027 0.305
## par_ct 6.913e-03 1.260e-02 0.548 0.583
## herd_size_ct 3.485e-03 3.148e-04 11.070 < 2e-16 ***
## herd_size_ct_sq 2.079e-05 4.557e-06 4.562 5.46e-06 ***
## twin 6.656e-01 1.546e-01 4.306 1.77e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7329 on 1561 degrees of freedom
## Multiple R-squared: 0.0826, Adjusted R-squared: 0.07966
## F-statistic: 28.11 on 5 and 1561 DF, p-value: < 2.2e-16Est-ce que les conclusions des tests de F ou de T changent comparativement au modèle calculé au début de la question 8?
Réponse: Les valeurs de P changent un peu mais aucune des conclusions n’est modifiée.
Est-ce que les estimés obtenus changent beaucoup ? Pour quel paramètre l’estimé semble être le plus affecté ? Est-ce en accord avec votre réponse à la question 8.d. ?
Réponse: Les estimés ne changent pas beaucoup. Le paramètre qui semble être le plus affecté est twin. Ce dernier passe de +0.45 log_wpc à +0.66 log_wpc lorsque les observations influentes sont retirées. C’est bien certainement en accord avec le fait que les observations les plus influentes sont des observations où twin=1.
6.12 Travaux pratiques 3 - Régression linéaire - Construction de modèle
6.12.1 Exercices
Les données utilisées pour ce TP sont obtenues à partir de la page du cours sur Studium. La base de données milk2 est disponible en format ASCII délimité (.csv).
Le jeu de données milk2 comprend 5 variables et 1140 observations:
breed race de la vache (1 = Ayrshire, 2 = Holstein, 3 = Jersey, 8 =mixed)
parity numéro de lactation
kgmilk production journalière de lait en kg
cellcount comptage en cellules somatiques x 10^3 cell./ml de lait
cowid identification de la vache
Vous souhaitez savoir quel est l’effet de la production laitière sur le comptage des cellules somatiques. Votre diagramme causal est le suivant:

Figure 6.21. Diagramme causal de la relation entre production laitière et comptage des cellules somatiques.
À partir du jeu de données fourni (milk2), répondre aux questions suivantes :
Quelles sont les variables confondantes que vous devrez possiblement contrôler pour répondre à votre question de recherche?
Quel serait votre modèle maximum?
Quelles sont les étapes que vous aurez à réaliser afin de développer et évaluer ce modèle statistique?
Évidemment, ce serait difficile de tout faire cela dans un TP de 3hrs. Dans les questions suivantes, vous n’aurez qu’à évaluer certains aspects de ce travail.
Que pensez-vous de la variable cellcount (données manquantes, distribution)? Pensez-vous que cette variable causera des problèmes plus tard? Si oui, que pourriez-vous faire?
Évaluez la variable parity. Peu de vaches ont eu 5, 6, 7 ou 8 lactations. Pensez-vous qu’il serait préférable de catégoriser cette variable (e.g. 1ère vs. 2ième vs. 3ième vs. 4ième vs. > 4ième)?
À propos de la relation entre kgmilk et cellcount :
6.1. Comment se comportent les résiduels (normalité et homoscédasticité) dans un modèle simple:
\(cellcount=β_0 + β_1*kgmilk\) ?
Et avec \(log(cellcount)=β_0 + β_1*kgmilk\)?Comme noté à la question 4, il semble qu’il serait mieux de travailler avec le logarithme naturel de cellcount qu’avec la variable originale. Continuez donc avec le log(cellcount) pour les analyses suivantes.
6.2. Comment est-ce que le log(cellcount) varie en fonction de kgmilk? Est-ce que cette relation est linéaire? Comment allez-vous modéliser cette relation dans vos analyses subséquentes?
Associations conditionnelles.
7.1. La relation entre parity et cellcount également n’était pas linéaire et vous devrez donc modéliser cette relation à l’aide de 2 termes : \(parity centrée\) et \(parity centrée^2\). Trouvez-vous que les coefficients pour la production laitière changent beaucoup lorsqu’on ajuste pour le facteur confondant parité ?
i.e. le modèle:
\(log(cellcount)=β_0 + β_1*kgmilk + β_2*kgmilk^2 + β_3*kgmilk^3 + β_4*parity + β_5*parity^2\)7.2. Trouvez-vous que les coefficients pour la production laitière changent beaucoup lorsqu’on ajuste pour race?
Afin de réduire votre modèle maximum, vous décidez de retirer du modèle les facteurs confondants hypothétiques qui causaient une modification relative < 10% de la mesure d’effet de kgmilk. Quel(s) facteur(s) confondant(s) gardez-vous? Y-a-t-il d’autres variables que vous désirez maintenant retirer du modèle? Quel serait votre modèle final?
Évaluez si les suppositions de votre modèle final sont respectées.
Évaluez les observations extrêmes, les leviers et les observations influentes (nombre, profil commun).
10.1. Quelle est la valeur de cellcount pour les observations avec les résiduels négatifs les plus larges?
10.2. Une valeur de 1,000 cell./ml est assez inusitée pour un comptage des cellules somatiques. En fait la limite analytique du Fossomatic cell counter est généralement de 10,000 cell./ml. Vous appelez donc le laboratoire pour en savoir plus sur ces résultats. On vous dit qu’on donne la valeur « 1 » aux échantillons qui ne peuvent être analysés (échappés, mal conservés, etc). Il s’agit donc d’observations manquantes! Vous pouvez donc ré-évaluer le modèle en excluant ces observations (et en priant pour que les résultats changent peu).
Notez comment votre Q-Q plot et l’histogramme des résiduels sont encore mieux sans ces observations. Combien d’observations avec un résiduel large (>3 ou <-3) avez-vous? Ces observations ont-elles quelque chose en commun?
10.3. Vérifiez maintenant les 10 observations avec les leviers les plus grands. Ont-elles quelque chose en commun?
10.4. Vérifiez maintenant les 10 observations les plus influentes. Ont-elles quelque chose en commun?Présentation des résultats.
11.1. Présentez les résultats de votre modèle dans une table que vous pourriez soumettre dans une publication scientifique.
L’effet de la production laitière n’est plus sur l’échelle originale. En plus, la relation entre production et CCS n’est pas linéaire. Tout ça rend votre modèle difficile à interpréter et il faudrait possiblement trouver une manière de rendre l’information plus digestible pour vos lecteurs.
11.2. Vous pourriez présenter comment le CCS varie en fonction de la production laitière pour différents scénarios. Vous pourriez, par exemple, compléter la table suivante, en calculant la valeur prédite pour chaque scénario à l’aide de votre modèle, puis en retransformant ces valeurs sur l’échelle originale:
| Production | 1ère lactation | 2ième lactation | 3ième et plus |
|---|---|---|---|
| 10kg/jour | |||
| 20kg/jour | |||
| 30kg/jour |
11.3. Encore mieux : à partir d’une table R contenant les valeurs prédites, retransformez la valeur prédite sur l’échelle originale en créant une nouvelle variable \(CCS=exp(valeur prédite)\). Ensuite, vous pourrez utiliser le package ggplot2 pour représenter dans un graphique de nuage de points la relation entre la production laitière (en x) et la valeur prédite de CCS (en y).
C’est plus simple à comprendre ainsi n’est-ce pas?
6.12.2 Code R et réponses
Les données utilisées pour ce TP sont obtenues à partir de la page du cours sur Studium. La base de données milk2 est disponible en format ASCII délimité (.csv).
#Ouvrir le jeu de données
milk2 <-read.csv(file="milk2.csv",
header=TRUE,
sep=";")Quelles sont les variables confondantes que vous devrez possiblement contrôler pour répondre à votre question de recherche?
Réponse: Parité et RaceQuel serait votre modèle maximum?
Réponse: \(cellcount = β_0 + β_1*kgmilk + β_2*breed + β_3*parity\)Quelles sont les étapes que vous aurez à réaliser afin de développer et évaluer ce modèle statistique?
Réponse:- Évaluer cellcount seul (données manquantes, distribution, transformation…)
- Évaluer individuellement kgmilk, breed et parity (données manquantes, distributions, table de fréquence, transformations pour centrer ou mettre à l’échelle, décider des catégories de référence…)
- Évaluer association inconditionnelle entre chaque prédicteur et cellcount (graphiques et modèles, linéarité de la relation pour les variables continues):
Pour Kgmilk:
- Nuage de points kgmilk x cellcount avec courbe loess pour linéarité
- Modèle \(cellcount = β_0 + β_1*kgmilk\)
- Modèle \(cellcount = β_0 + β_1*kgmilk + β_2*kgmilk^2\) (pour évaluer la forme de la relation)
- Modèle \(cellcount = β_0 + β_1*kgmilk + β_2*kgmilk^2 + kgmilk^3\) (pour évaluer la forme de la relation)
Pour Breed:
- Box-plot cellcount x breed
- Modèle \(cellcount = β_0 + β_1*breed\)
Pour Parity:
- Nuage de points avec loess ou box-plot cellcount x parity pour linéarité
- Modèle \(cellcount = β_0 + β_1*parity\)
- Modèle \(cellcount = β_0 + β_1*parity + β_2*parity^2\) (pour évaluer la forme de la relation)
- Modèle \(cellcount = β_0 + β_1*parity + β_2*parity^2 + parity^3\) (pour évaluer la forme de la relation)
- Évaluer les associations inconditionnelles entre prédicteurs
Pour Kgmilk et breed:
- Boxplot kgmilk x breed
- Modèle \(kgmilk=β_0 + β_1*breed\)
Pour Parity et breed:
- Boxplot parity x breed
- Modèle \(parity=β_0 + β_1*breed\)
Pour Kgmilk et parity: - Nuage de points kgmilk x parity avec courbe loess
- Modèle \(kgmilk=β_0 + β_1*parity\)
- Évaluer les associations conditionnelles (i.e. après avoir ajouté un confondant):
Breed (confondant)
- Modèle \(cellcount=β_0 + β_1*kgmilk + β_2*breed\)
Parity (confondant)
- Modèle \(cellcount=β_0 + β_1*kgmilk + β_2*Parity\)
Notez : s’il y avait eu une interaction à investiguer, c’est à ce stade-ci que vous auriez pu évaluer le modèle avec juste l’interaction. Par exemple: \(cellcount= β_0 + β_1*kgmilk + β_2*parity + β_3*kgmilk*parity\)
- S’il y a lieu, éÉtablir une stratégie de sélection des covariables qui permettra de réduire le modèle maximum
Confondants : par exemple on peut choisir de réduire le nombre de facteurs confondants en vérifiant si les associations conditionnelle et inconditionnelle diffèrent par plus de 10%
Notez : s’il y avait eu une interaction à investiguer, c’est à ce stade-ci que vous auriez pu spécifier quels critères seront utilisés pour décider des interactions à retenir. Par exemple : si le(s) terme(s) d’interaction à une valeur de P < 0.05, alors garder l’interaction et les termes principaux.
- Évaluer le modèle
Suppositions (homoscédasticité et normalité)
Observations:
- Extrêmes (résiduels)
- Combinaisons de prédicteurs (leviers)
- Influentes (Cook’s distance)
- Évaluer cellcount seul (données manquantes, distribution, transformation…)
Évidemment, ce serait difficile de tout faire cela dans un TP de 3hrs. Dans les questions suivantes, vous n’aurez qu’à évaluer certains aspects de ce travail.
- Que pensez-vous de la variable cellcount (données manquantes, distribution)? Pensez-vous que cette variable causera des problèmes plus tard? Si oui, que pourriez-vous faire ?
#Le package summarytools est utile pour les analyses descriptives. Ici nous demandons les stats descriptives pour toute les variables de milk2.
#Nous aurions aussi pu spécifier milk2$cellcount pour ne voir que cellcount.
#Dans un script RMarkdown, ont doit aussi spécifier method='render'. Cet argument n'est pas nécessaire sinon.
library(summarytools)
print(dfSummary(milk2),
method='render')Data Frame Summary
Dimensions: 1140 x 5Duplicates: 54
| No | Variable | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | breed [integer] |
|
|
 |
1140 (100.0%) | 0 (0.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | parity [integer] |
|
|
 |
1139 (99.9%) | 1 (0.1%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | kgmilk [numeric] |
|
269 distinct values |  |
1140 (100.0%) | 0 (0.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | cellcount [integer] |
|
422 distinct values |  |
1140 (100.0%) | 0 (0.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | cowid [integer] |
|
1086 distinct values |  |
1140 (100.0%) | 0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.0)
2023-01-19
Réponse: Pour cellcount, il n’y a pas de données manquantes, la distribution est skewed à droite. Oui, les résiduels seront probablement skewed aussi. Nous pourrions déjà vérifier si une transformation (par exemple un log naturel) améliorerait sa distribution :
milk2$log_cell <- log(milk2$cellcount)
print(dfSummary(milk2$log_cell),
method='render')## milk2$log_cell was converted to a data frameData Frame Summary
milk2
Dimensions: 1140 x 1Duplicates: 718
| No | Variable | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | milk2 [numeric] |
|
422 distinct values |  |
1140 (100.0%) | 0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.0)
2023-01-19
- Évaluez la variable parity. Peu de vaches ont eu 5, 6, 7 ou 8 lactations. Pensez-vous qu’il serait préférable de catégoriser cette variable (e.g. 1ère vs. 2ième vs. 3ième vs. 4ième vs. > 4ième)?
Réponse: Voir les résultats descriptifs précédents. Non, parce qu’elle est utilisée comme facteur confondant. Nous préférons donc conserver la mesure la plus précise possible afin d’avoir le meilleur contrôle possible. S’il s’agissait d’une exposition, nous pourrions effectivement considérer cette catégorisation.
À propos de la relation entre kgmilk et cellcount :
6.1. Comment se comportent les résiduels (normalité et homoscédasticité) dans un modèle simple:
\(cellcount=β_0 + β_1*kgmilk\) ?
Et avec \(log(cellcount)=β_0 + β_1*kgmilk\)?
#Le modèle avec cellcount et les figures de Dx des résiduels
model_cellcount <- lm(data=milk2,
cellcount ~ kgmilk)
plot(model_cellcount, 1) 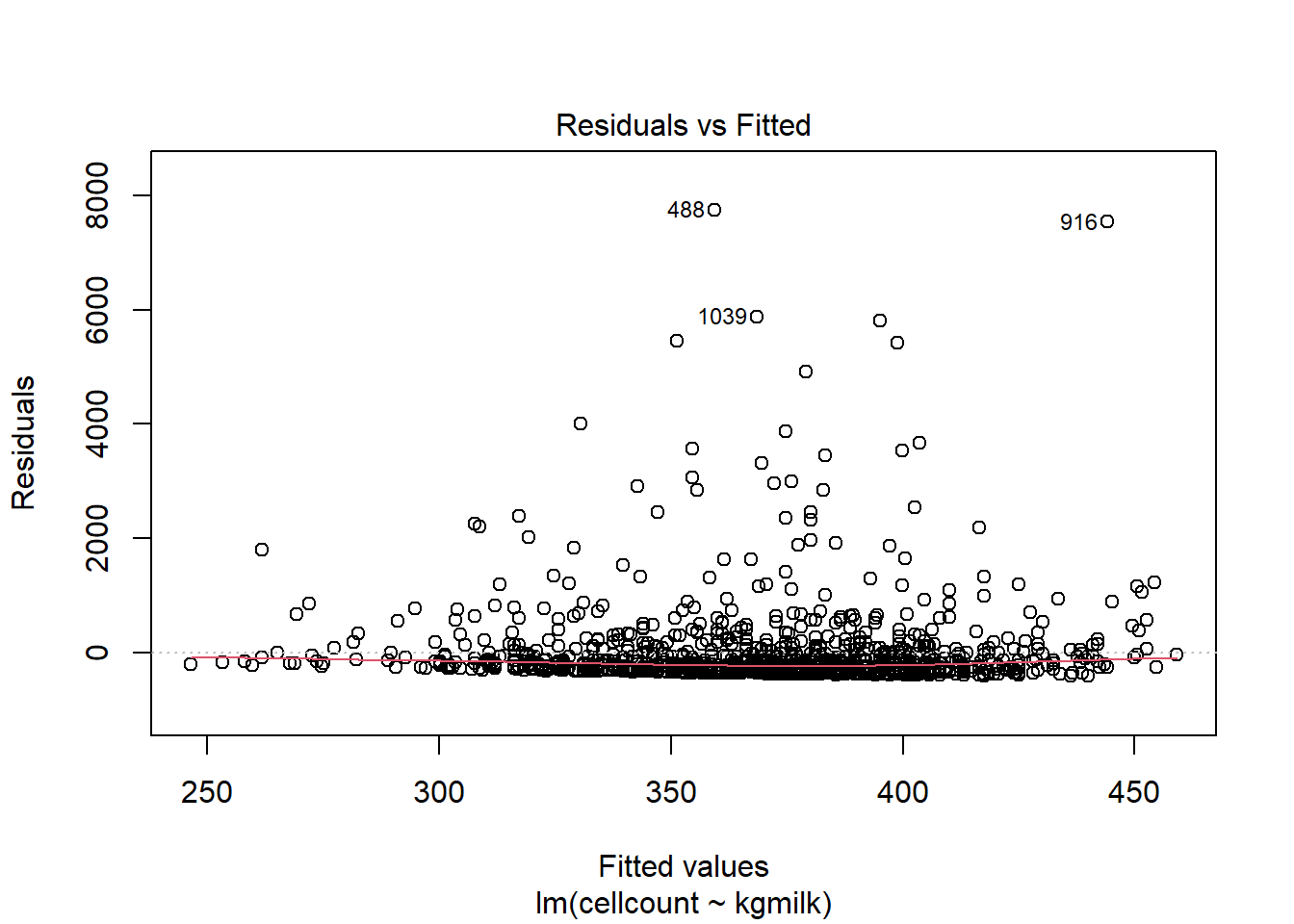
Figure 6.21: Graphiques des résiduels x valeurs prédites.
plot(model_cellcount, 2)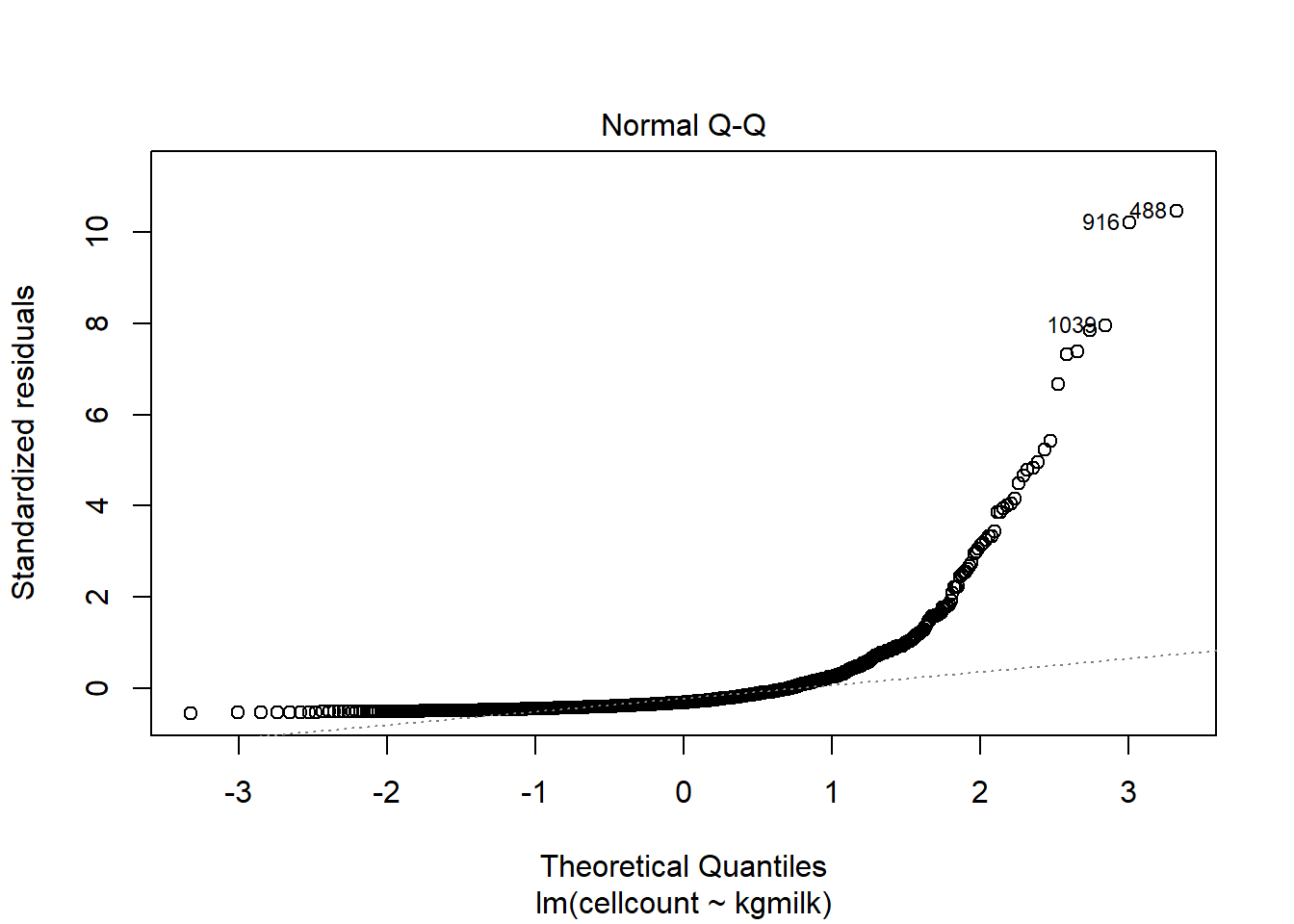
Figure 6.22: Graphiques Q-Q des résiduels.
Réponse: Problème de normalité et possiblement homoscédasticité!
#Le modèle avec le logarithme de cellcount et les figures de Dx des résiduels
model_log_cell <- lm(data=milk2,
log_cell ~ kgmilk)
plot(model_log_cell, 1) 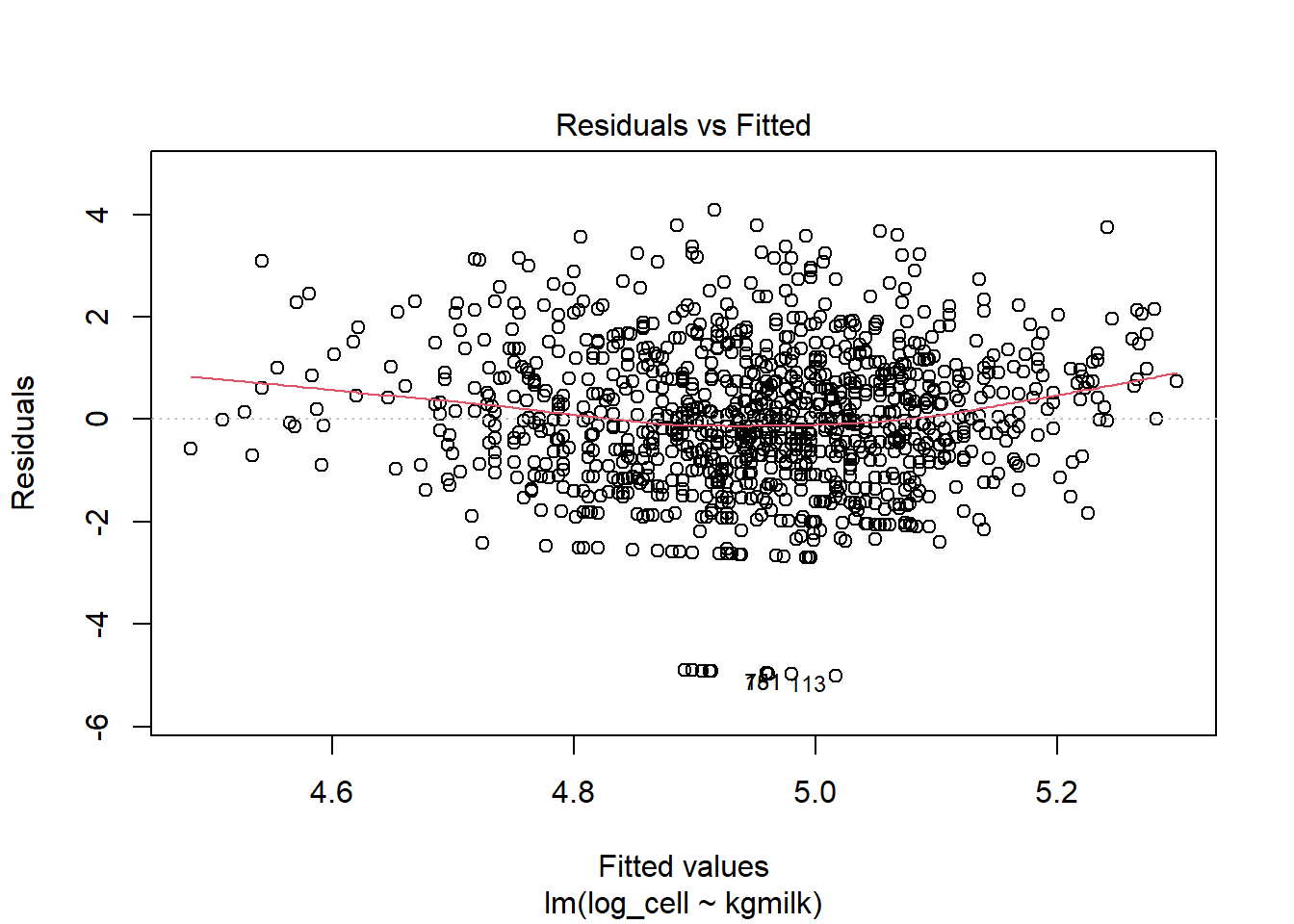
Figure 6.23: Graphiques des résiduels x valeurs prédites.
plot(model_log_cell, 2)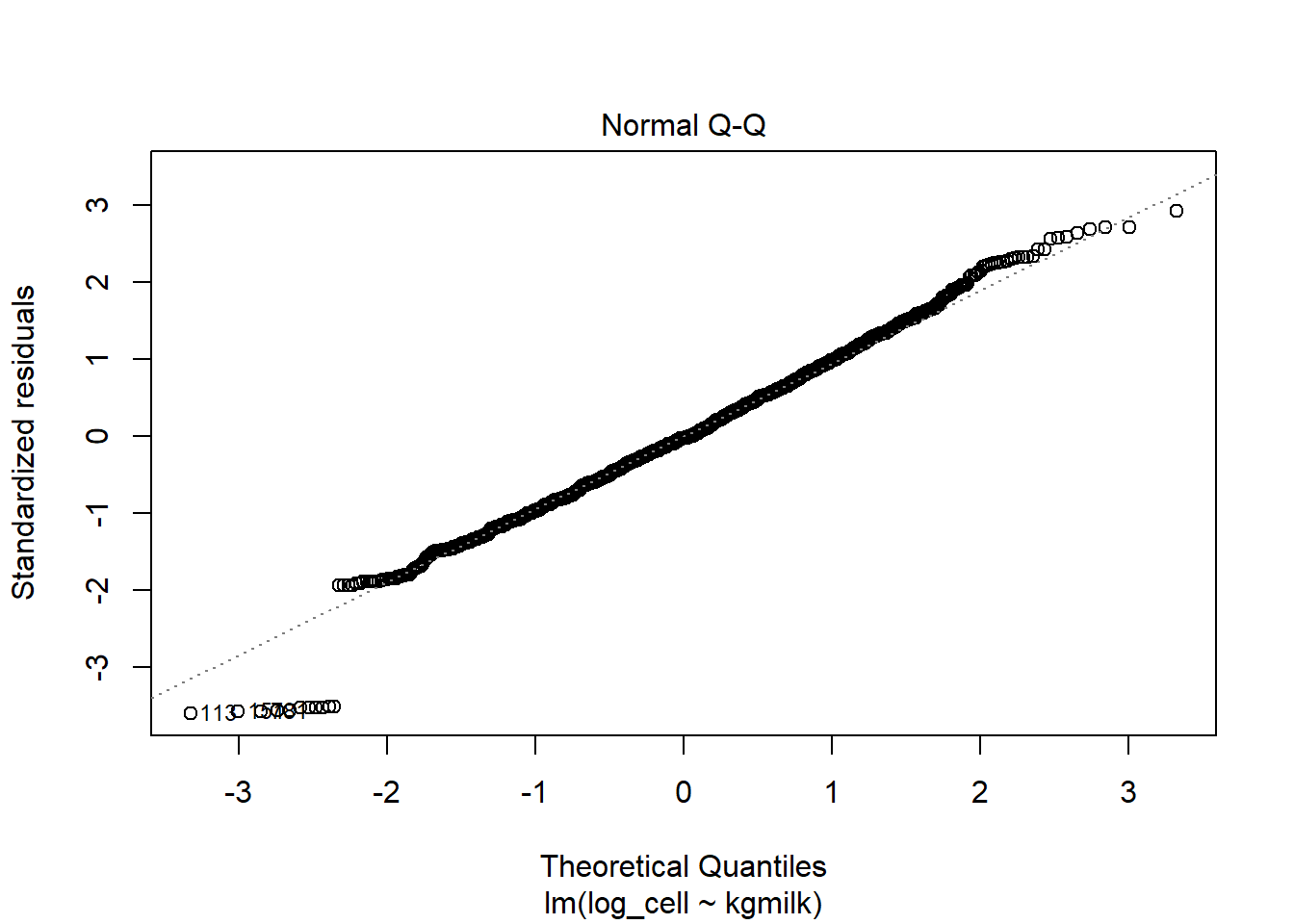
Figure 6.24: Graphiques Q-Q des résiduels.
Réponse: Dans le modèle avec le logarithme naturel de cellcount c’est beaucoup mieux.
Comme noté à la question 4, il semble qu’il serait mieux de travailler avec le logarithme naturel de cellcount qu’avec la variable originale. Continuez donc avec le log(cellcount) pour les analyses suivantes.
6.2. Comment est-ce que log(cellcount) varie en fonction de kgmilk? Est-ce que cette relation est linéaire? Comment allez-vous modéliser cette relation dans vos analyses subséquentes?
library(ggplot2)
ggplot(milk2,
aes(kgmilk, log_cell)
) +
geom_point() +
geom_smooth(method="loess",
span=2) +
theme_bw() 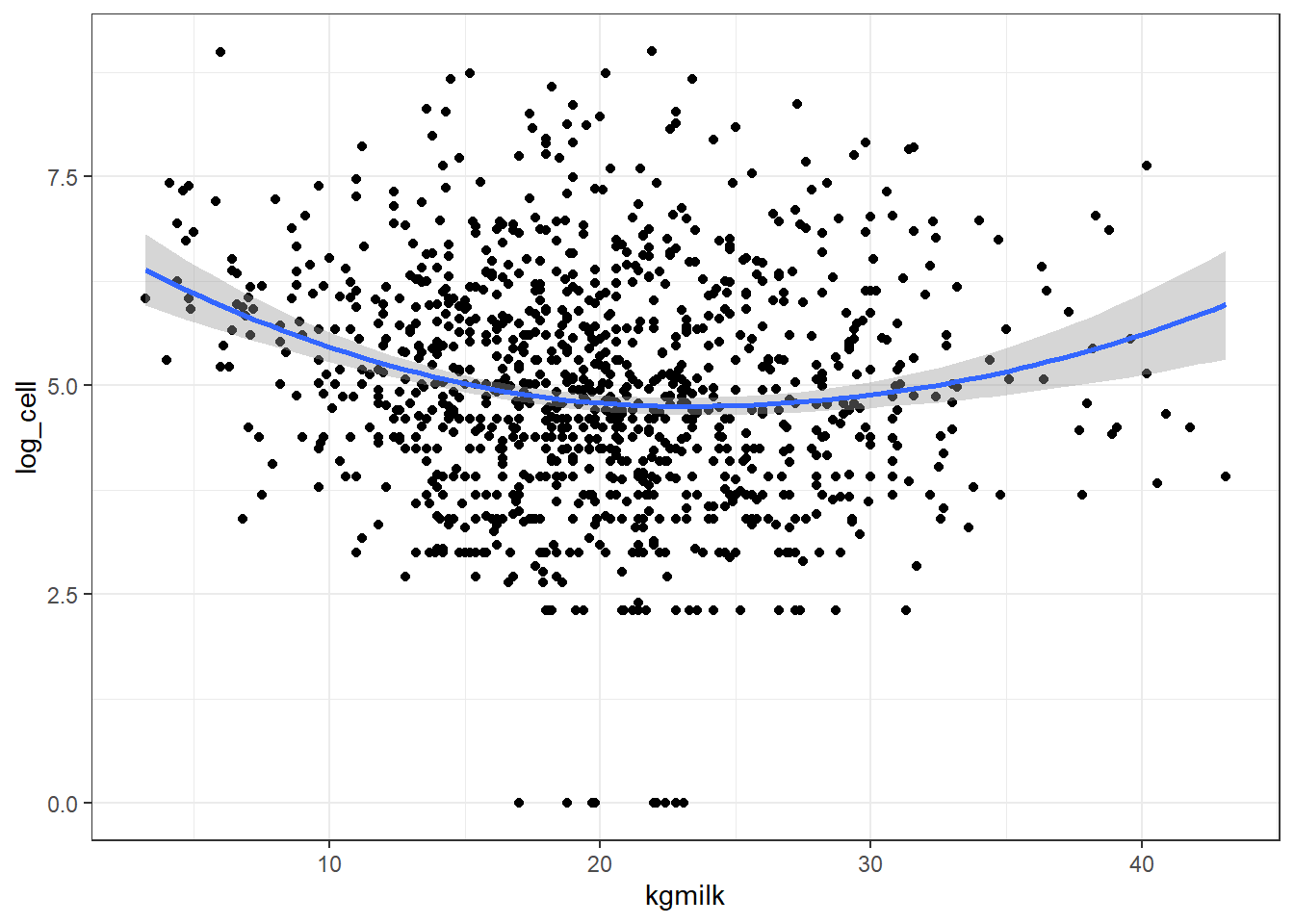
Figure 6.25: Relation entre la production laitière (en kg/j) et le logarithme naturel de cellcount avec courbe lissée avec un facteur de 2.
Réponse: Le logarithme de cellcount diminue avec la production puis augmente (i.e. une courbe). La relation n’est pas linéaire. Vérifions avec les termes polynomiaux…
#D'abord, centrons kgmilk sur une valeur près de la moyenne (pour éviter la colinéarité)
milk2$kgmilk_ct <- milk2$kgmilk-20
#Puis créons des termes au carré et au cube
milk2$kgmilk_ct_sq <- milk2$kgmilk_ct*milk2$kgmilk_ct
milk2$kgmilk_ct_cu <- milk2$kgmilk_ct*milk2$kgmilk_ct*milk2$kgmilk_ct
#Vérifions le modèle avec le terme au carré
model_sq <- lm(data=milk2,
log_cell ~ (kgmilk_ct + kgmilk_ct_sq)
)
summary(model_sq)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq), data = milk2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.9196 -0.9167 -0.0497 0.8787 4.2372
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.8028594 0.0491544 97.710 < 2e-16 ***
## kgmilk_ct -0.0281185 0.0064195 -4.380 1.30e-05 ***
## kgmilk_ct_sq 0.0035949 0.0006477 5.551 3.54e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.376 on 1137 degrees of freedom
## Multiple R-squared: 0.03517, Adjusted R-squared: 0.03347
## F-statistic: 20.72 on 2 and 1137 DF, p-value: 1.448e-09Réponse: Le terme au carré est significatif (P < 0.05)
#Vérifions le modèle avec le terme au carré et le terme au cube
model_cu <- lm(data=milk2,
log_cell ~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu)
)
summary(model_cu)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu),
## data = milk2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.8668 -0.9016 -0.0672 0.8875 4.2224
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.787e+00 4.974e-02 96.235 < 2e-16 ***
## kgmilk_ct -1.282e-02 1.007e-02 -1.273 0.2031
## kgmilk_ct_sq 4.236e-03 7.241e-04 5.850 6.41e-09 ***
## kgmilk_ct_cu -1.185e-04 6.014e-05 -1.970 0.0491 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.375 on 1136 degrees of freedom
## Multiple R-squared: 0.03845, Adjusted R-squared: 0.03591
## F-statistic: 15.14 on 3 and 1136 DF, p-value: 1.145e-09Réponse: Le terme au cube est aussi significatif (P < 0.05). Cette relation devrait donc être modélisée en utilisant \(kgmilk + kgmilk^2 + kgmilk^3\)
Associations conditionnelles.
7.1. La relation entre parity et cellcount également n’était pas linéaire et vous devrez donc modéliser cette relation à l’aide de 2 termes : \(parity\) et \(parity^2\). Trouvez-vous que les coefficients pour la production laitière changent beaucoup lorsqu’on ajuste pour le facteur confondant parité ?
i.e. le modèle:
\(log(cellcount)=β_0 + β_1*kgmilk + β_2*kgmilk^2 + β_3*kgmilk^3 + β_4*parity + β_5*parity^2\)
#Générons ces nouvelles variables parité centrée sur parité 1
milk2$parity_ct <- milk2$parity-1
milk2$parity_ct_sq <- milk2$parity_ct*milk2$parity_ct
#Vérifions les modèles avec et sans ajustement pour parity (nous avons déjà fait rouler celui sans parity à la question 6.2)
model_parity <- lm(data=milk2,
log_cell~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu + parity_ct + parity_ct_sq)
)
summary(model_parity)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu +
## parity_ct + parity_ct_sq), data = milk2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2194 -0.8303 -0.0055 0.8096 4.1204
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.383e+00 6.476e-02 67.679 < 2e-16 ***
## kgmilk_ct -3.452e-02 9.947e-03 -3.471 0.000539 ***
## kgmilk_ct_sq 2.985e-03 7.087e-04 4.212 2.73e-05 ***
## kgmilk_ct_cu -6.589e-05 5.816e-05 -1.133 0.257514
## parity_ct 5.102e-01 7.125e-02 7.161 1.44e-12 ***
## parity_ct_sq -5.742e-02 1.514e-02 -3.794 0.000156 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.323 on 1133 degrees of freedom
## (1 observation effacée parce que manquante)
## Multiple R-squared: 0.1114, Adjusted R-squared: 0.1075
## F-statistic: 28.41 on 5 and 1133 DF, p-value: < 2.2e-16Réponse: Oui voir table suivante (notez que j’ai arrondi les estimés avant de faire les calculs). Notez aussi, le \(kgmilk^3\) n’est plus significatif (P = 0.26) après avoir ajusté pour parité (i.e. \(kgmilk^3\) ne serait plus nécessaire après ajustement pour parité).
| Inconditionnelle | Conditionelle | Diff_relative_parity | |
|---|---|---|---|
| kgmilk_ct | -0.0128 | -0.0345 | -170 |
| kgmilk_ct_sq | 0.0042 | 0.0030 | 29 |
| kgmilk_ct_cu | -0.0001 | -0.0001 | 0 |
7.2. Trouvez-vous que les coefficients pour la production laitière changent beaucoup lorsqu’on ajuste pour race?
#Vérifions les modèles avec ajustement pour race
model_breed <- lm(data=milk2,
log_cell~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu + factor(breed))
)
summary(model_breed)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu +
## factor(breed)), data = milk2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.9882 -0.8871 -0.0977 0.8370 4.0193
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.853e+00 1.117e-01 43.433 < 2e-16 ***
## kgmilk_ct -2.860e-02 1.026e-02 -2.787 0.00541 **
## kgmilk_ct_sq 3.754e-03 7.168e-04 5.237 1.94e-07 ***
## kgmilk_ct_cu -7.864e-05 5.960e-05 -1.320 0.18726
## factor(breed)2 1.880e-01 1.233e-01 1.524 0.12775
## factor(breed)3 -5.860e-01 1.454e-01 -4.029 5.98e-05 ***
## factor(breed)8 -1.474e-01 1.361e-01 -1.083 0.27923
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.35 on 1133 degrees of freedom
## Multiple R-squared: 0.0749, Adjusted R-squared: 0.07
## F-statistic: 15.29 on 6 and 1133 DF, p-value: < 2.2e-16Réponse: Notez que j’ai du indiquer que breed est une variable catégorique (parce que, dans la base de données, les catégories de races sont indiquées par des chiffres, ce qui peut laisser croire à R qu’il s’agit d’une variable quantitative). Voir la table suivante où je présente les estimés ajustés ou non pour breed.
| Inconditionnelle | Conditionelle | Diff_relative_breed | |
|---|---|---|---|
| kgmilk_ct | -0.0128 | -0.0286 | -123 |
| kgmilk_ct_sq | 0.0042 | 0.0038 | 10 |
| kgmilk_ct_cu | -0.0001 | -0.0001 | 0 |
- Afin de réduire votre modèle maximum, vous décidez de retirer du modèle les facteurs confondants hypothétiques qui causaient une modification relative < 10% de la mesure d’effet de kgmilk. Quel(s) facteur(s) confondant(s) gardez-vous? Y-a-t-il d’autres variables que vous désirez maintenant retirer du modèle? Quel serait votre modèle final?
Réponse: Parité et race seront inclus comme facteur confondant (i.e. \(parity + parity^2 + breed\)). Ces deux variables créaient des changements importants (123 à 170% de différence relative) pour au moins un des termes kgmilk. Notez que l’ajout de point d’inflexion (i.e. \(kgmilk^3\)) n’est plus nécessaire maintenant (voir résultats plus bas). Ce terme pourrait être retiré.
model_max <- lm(data=milk2,
log_cell~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu + parity_ct + parity_ct_sq + factor(breed))
)
summary(model_max)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq + kgmilk_ct_cu +
## parity_ct + parity_ct_sq + factor(breed)), data = milk2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.3616 -0.8233 -0.0648 0.8125 4.1456
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.406e+00 1.146e-01 38.463 < 2e-16 ***
## kgmilk_ct -5.924e-02 1.011e-02 -5.857 6.18e-09 ***
## kgmilk_ct_sq 2.260e-03 6.934e-04 3.259 0.00115 **
## kgmilk_ct_cu -2.915e-06 5.701e-05 -0.051 0.95923
## parity_ct 5.745e-01 6.950e-02 8.265 3.88e-16 ***
## parity_ct_sq -6.241e-02 1.468e-02 -4.252 2.29e-05 ***
## factor(breed)2 2.043e-01 1.174e-01 1.741 0.08201 .
## factor(breed)3 -7.932e-01 1.395e-01 -5.685 1.66e-08 ***
## factor(breed)8 -9.039e-02 1.296e-01 -0.697 0.48573
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.282 on 1130 degrees of freedom
## (1 observation effacée parce que manquante)
## Multiple R-squared: 0.1679, Adjusted R-squared: 0.162
## F-statistic: 28.5 on 8 and 1130 DF, p-value: < 2.2e-16Le modèle final serait: \(Log(cellcount) = β_0 + β_1*kgmilk + β_2*kgmilk^2 + β_3*parity + β_4*parity^2 + β_5*breed\) et voici les résultats de ce modèle:
model_final <- lm(data=milk2,
log_cell~ (kgmilk_ct + kgmilk_ct_sq + parity_ct + parity_ct_sq + factor(breed))
)
summary(model_final)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq + parity_ct +
## parity_ct_sq + factor(breed)), data = milk2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.3612 -0.8246 -0.0672 0.8113 4.1447
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.406646 0.114237 38.574 < 2e-16 ***
## kgmilk_ct -0.059636 0.006509 -9.161 < 2e-16 ***
## kgmilk_ct_sq 0.002244 0.000615 3.648 0.000276 ***
## parity_ct 0.574849 0.069058 8.324 2.43e-16 ***
## parity_ct_sq -0.062466 0.014629 -4.270 2.12e-05 ***
## factor(breed)2 0.204097 0.117247 1.741 0.081999 .
## factor(breed)3 -0.794119 0.138230 -5.745 1.18e-08 ***
## factor(breed)8 -0.090508 0.129543 -0.699 0.484900
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.281 on 1131 degrees of freedom
## (1 observation effacée parce que manquante)
## Multiple R-squared: 0.1679, Adjusted R-squared: 0.1628
## F-statistic: 32.6 on 7 and 1131 DF, p-value: < 2.2e-16- Évaluez si les suppositions de votre modèle final sont respectées.
Réponse: Homoscédasticité semble OK (voir figure plus bas). Il ne semble pas y avoir d’augmentation ou de diminution flagrante de la variance des résiduels (à l’exception des extrémités, mais il y a très peu d’observations avec une valeur prédite > 6).
plot(model_final, 1) 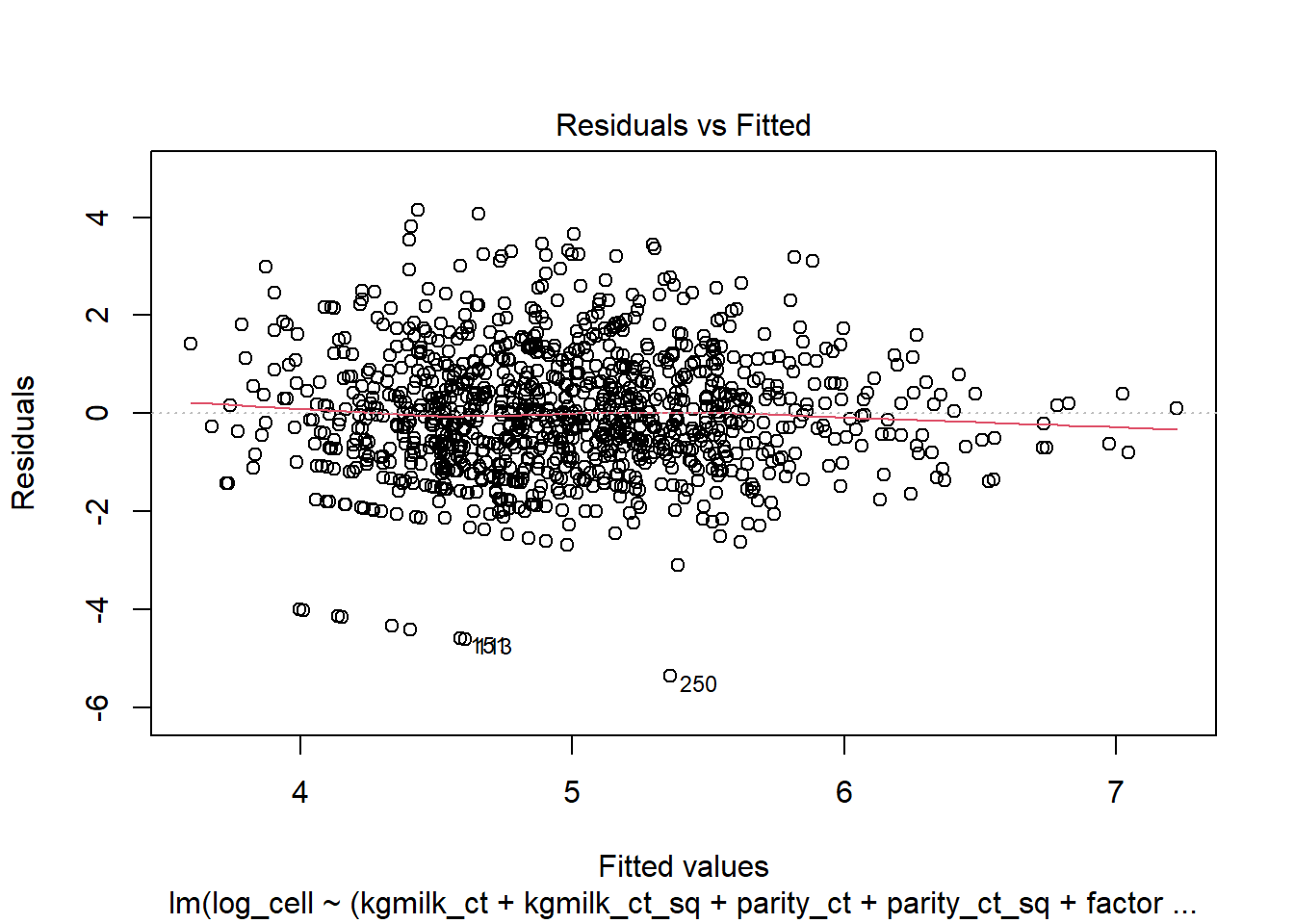
Figure 6.26: Graphiques des résiduels x valeurs prédites.
Réponse: Normalité des résiduels semble OK (voir figure plus bas). Il y a à peine une 30aine d’observations qui ne tombent pas sur la droite de 45 degrés).
plot(model_final, 2) 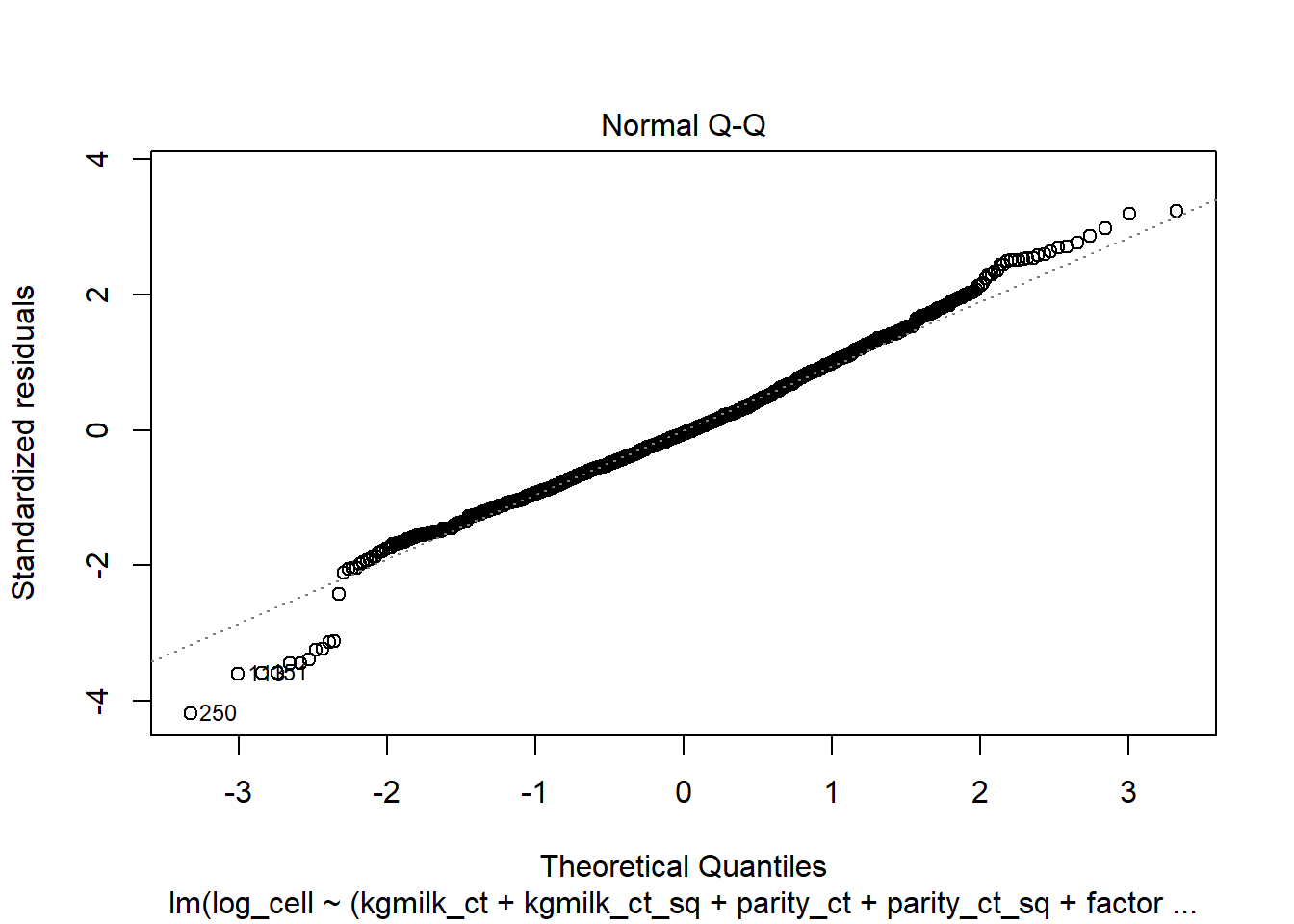
Figure 6.27: Graphiques Q-Q des résiduels
- Évaluez les observations extrêmes, leviers et influentes (nombre, profil commun).
10.1. Quelle est la valeur de cellcount pour les observations avec les résiduels négatifs les plus larges?
library(broom)
diag <- augment(model_final) #Nous créons un nouveau jeu de données dans laquelle les résiduels, distance de cook, etc, se trouvent maintenant
diag_res <- subset(diag, (.std.resid < -3.0)) #Gardons seulement les résiduels standardisés <-3.0
diag_res <- diag_res[order(-diag_res$.std.resid),] #Plaçons les résiduels en ordre décroissant
diag_res <- na.omit(diag_res) #Enlever les valeurs manquantes| .rownames | log_cell | kgmilk_ct | kgmilk_ct_sq | parity_ct | parity_ct_sq | factor(breed) | .fitted | .resid | .hat | .sigma | .cooksd | .std.resid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 107 | 0 | 2.4 | 5.76 | 1 | 1 | 3 | 3.994707 | -3.994707 | 0.0069269 | 1.276052 | 0.0085374 | -3.129175 |
| 114 | 0 | 2.1 | 4.41 | 1 | 1 | 3 | 4.009569 | -4.009569 | 0.0068426 | 1.276011 | 0.0084950 | -3.140684 |
| 100 | 0 | -0.2 | 0.04 | 1 | 1 | 3 | 4.136926 | -4.136926 | 0.0062477 | 1.275652 | 0.0082471 | -3.239472 |
| 595 | 0 | 3.1 | 9.61 | 0 | 0 | 8 | 4.152829 | -4.152829 | 0.0052622 | 1.275612 | 0.0069859 | -3.250314 |
| 594 | 0 | -0.3 | 0.09 | 0 | 0 | 8 | 4.334230 | -4.334230 | 0.0048561 | 1.275078 | 0.0070164 | -3.391600 |
| 155 | 0 | 2.0 | 4.00 | 2 | 4 | 3 | 4.402063 | -4.402063 | 0.0070718 | 1.274856 | 0.0105873 | -3.448521 |
| 785 | 0 | 2.0 | 4.00 | 2 | 4 | 3 | 4.402063 | -4.402063 | 0.0070718 | 1.274856 | 0.0105873 | -3.448521 |
| 151 | 0 | -1.2 | 1.44 | 2 | 4 | 3 | 4.587153 | -4.587153 | 0.0065241 | 1.274278 | 0.0105943 | -3.592527 |
| 781 | 0 | -1.2 | 1.44 | 2 | 4 | 3 | 4.587153 | -4.587153 | 0.0065241 | 1.274278 | 0.0105943 | -3.592527 |
| 113 | 0 | -3.0 | 9.00 | 0 | 0 | 1 | 4.605745 | -4.605745 | 0.0074727 | 1.274212 | 0.0122567 | -3.608812 |
| 250 | 0 | 2.8 | 7.84 | 2 | 4 | 2 | 5.361186 | -5.361186 | 0.0036766 | 1.271613 | 0.0081088 | -4.192724 |
Réponse: le log(cellcount) est 0.0 (donc un cellcount de 1 x 1000 cellules/ml).
10.2. Une valeur de 1,000 cell./ml est assez inusitée pour un comptage des cellules somatiques. En fait la limite analytique du Fossomatic cell counter est généralement de 10,000 cell./ml. Vous appelez donc le laboratoire pour en savoir plus sur ces résultats. On vous dit qu’on donne la valeur « 1 » aux échantillons qui ne peuvent être analysés (échappés, mal conservés, etc). Il s’agit donc d’observations manquantes! Vous pouvez donc ré-évaluer le modèle en excluant ces observations (et en priant pour que les résultats changent peu).
milk2_corrected <- subset(milk2, milk2$cellcount>10)
milk2_corrected$breed <- factor(milk2_corrected$breed)
model_final2 <- lm(data=milk2_corrected,
log_cell~ (kgmilk_ct + kgmilk_ct_sq + parity_ct + parity_ct_sq + breed)
)
summary(model_final2)##
## Call:
## lm(formula = log_cell ~ (kgmilk_ct + kgmilk_ct_sq + parity_ct +
## parity_ct_sq + breed), data = milk2_corrected)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.6932 -0.8179 -0.1134 0.7179 4.0391
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.5993247 0.1070076 42.981 < 2e-16 ***
## kgmilk_ct -0.0472845 0.0060207 -7.854 9.61e-15 ***
## kgmilk_ct_sq 0.0014894 0.0005636 2.643 0.00834 **
## parity_ct 0.5513005 0.0638717 8.631 < 2e-16 ***
## parity_ct_sq -0.0595009 0.0135340 -4.396 1.21e-05 ***
## breed2 0.0759856 0.1090067 0.697 0.48591
## breed3 -0.6004440 0.1300708 -4.616 4.37e-06 ***
## breed8 -0.1529191 0.1207002 -1.267 0.20545
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.168 on 1093 degrees of freedom
## (1 observation effacée parce que manquante)
## Multiple R-squared: 0.1512, Adjusted R-squared: 0.1458
## F-statistic: 27.81 on 7 and 1093 DF, p-value: < 2.2e-16plot(model_final2, 1) 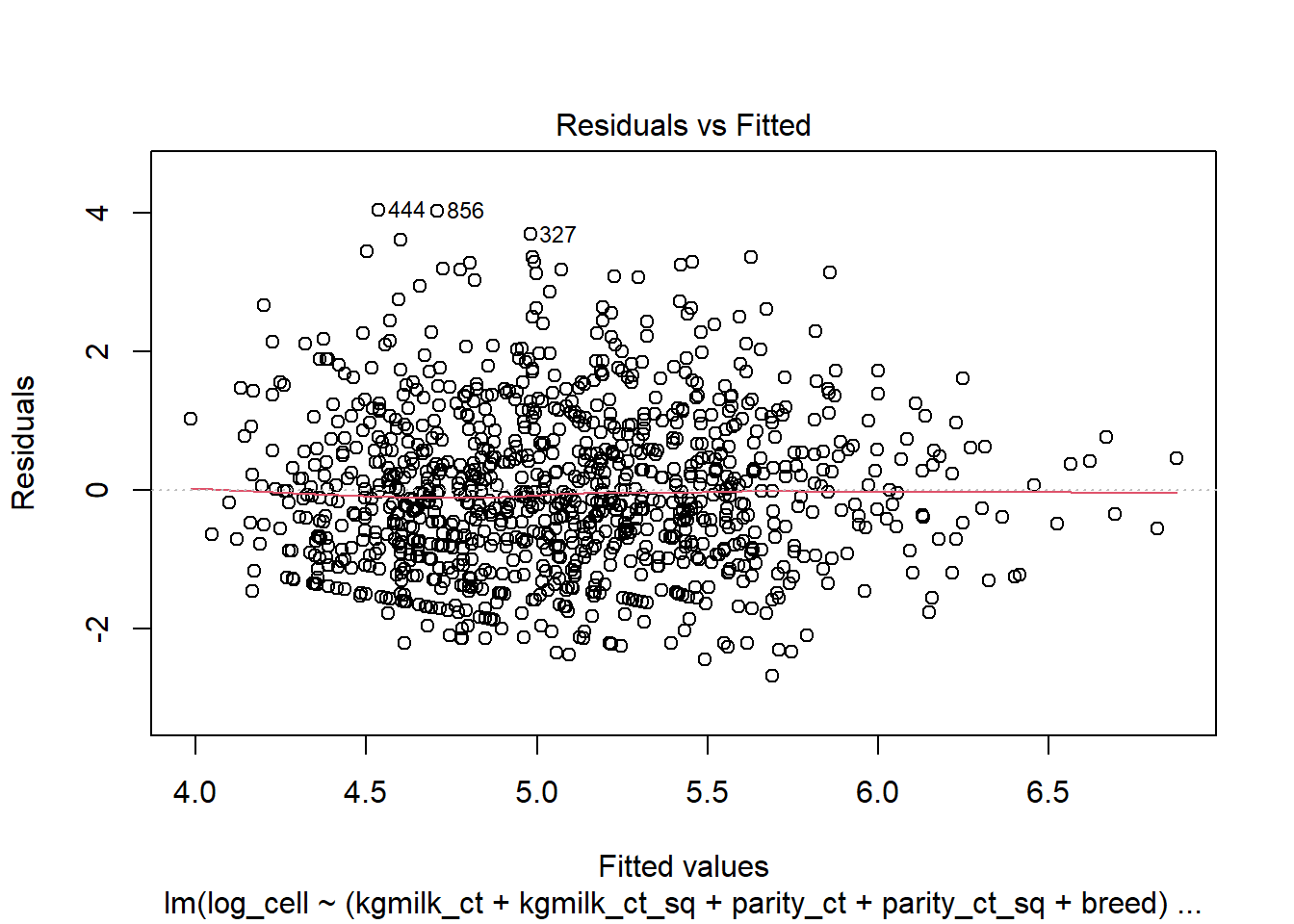
Figure 6.28: Graphiques des résiduels x valeurs prédites.
plot(model_final2, 2)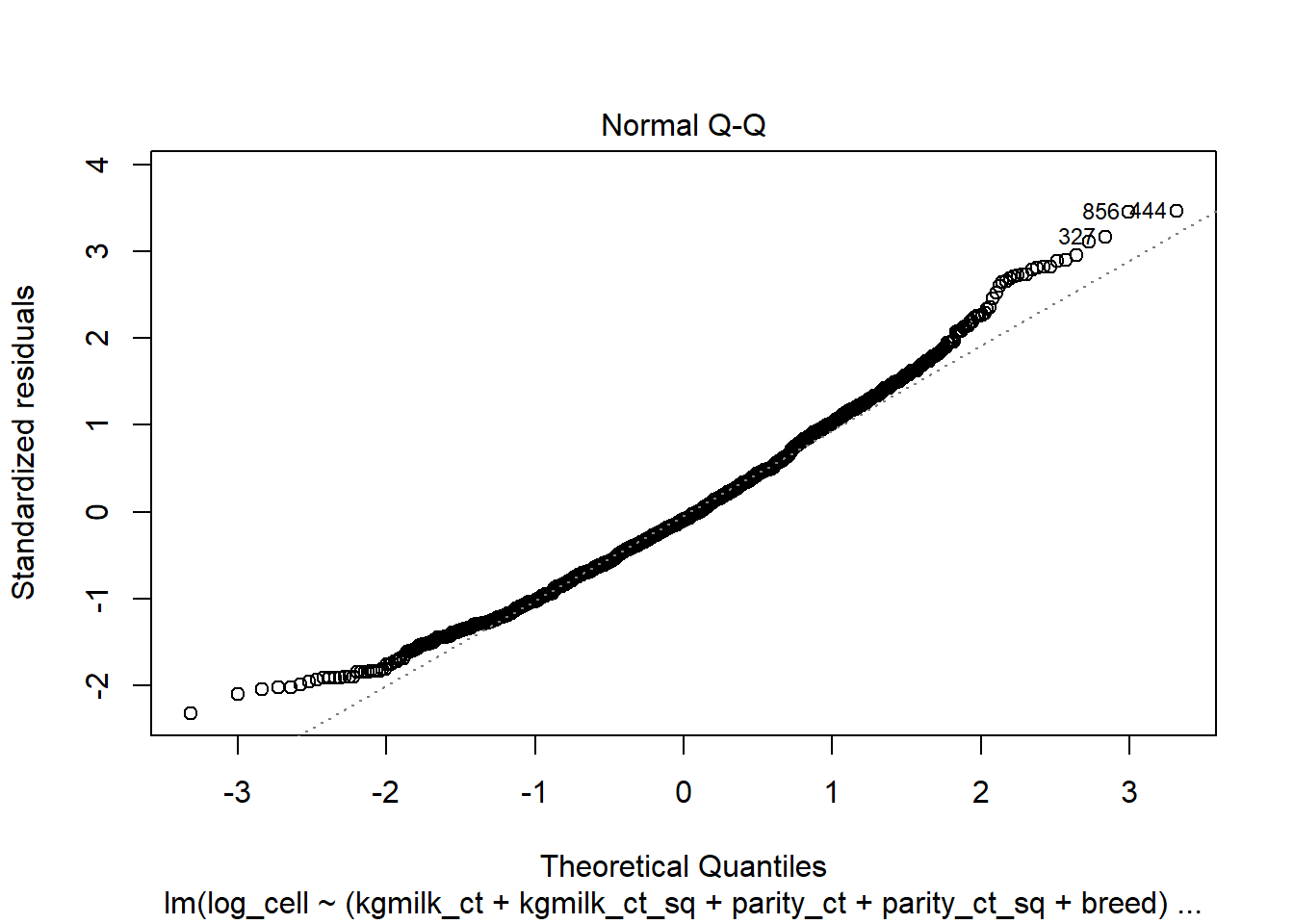
Figure 6.29: Graphiques Q-Q des résiduels.
Notez comment votre Q-Q plot et l’histogramme des résiduels sont encore mieux sans ces observations. Combien d’observations avec un résiduel large (>3 ou <-3) avez-vous? Ces observations ont-elles quelque chose en commun?
library(broom)
diag <- augment(model_final2)
diag_res <- subset(diag, (.std.resid < -3.0 | .std.resid > 3.0)) #Gardons seulement les résiduels standardisés <-3.0 ou >3.0
diag_res <- diag_res[order(diag_res$.std.resid),] #Plaçons les résiduels en ordre croissant
diag_res <- na.omit(diag_res) #Enlever les valeurs manquantes| .rownames | log_cell | kgmilk_ct | kgmilk_ct_sq | parity_ct | parity_ct_sq | breed | .fitted | .resid | .hat | .sigma | .cooksd | .std.resid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1078 | 8.214465 | 0.0 | 0.00 | 0 | 0 | 1 | 4.599325 | 3.615140 | 0.0083997 | 1.162928 | 0.0102372 | 3.109376 |
| 327 | 8.667852 | -5.5 | 30.25 | 0 | 0 | 2 | 4.980429 | 3.687423 | 0.0038030 | 1.162744 | 0.0047777 | 3.164221 |
| 856 | 8.731498 | -4.8 | 23.04 | 0 | 0 | 8 | 4.707686 | 4.023811 | 0.0053392 | 1.161708 | 0.0080121 | 3.455545 |
| 444 | 8.575462 | -1.8 | 3.24 | 0 | 0 | 8 | 4.536343 | 4.039119 | 0.0050420 | 1.161661 | 0.0076191 | 3.468173 |
Réponse: Il y a seulement 4 observations extrêmes. Seulement des résiduels positifs (i.e. le modèle sous-estime la vraie valeur). Toutes des 1ère lactation. Un cellcount élevé (i.e. > 3,000,000 cell./ml), mais des production assez moyennes. Différentes races. Le modèle a donc de la difficulté (i.e. il sous estime) la valeur de cellcount pour les vaches de 1ère lactation avec un cellcount élevé.
10.3. Vérifiez maintenant les 10 observations avec les leviers les plus grands. Ont-elles quelque chose en commun?
diag_hat <- diag[order(-diag$.hat),]
levier <- head(diag_hat, 10)| .rownames | log_cell | kgmilk_ct | kgmilk_ct_sq | parity_ct | parity_ct_sq | breed | .fitted | .resid | .hat | .sigma | .cooksd | .std.resid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 445 | 6.975414 | 14.0 | 196.00 | 7 | 49 | 2 | 5.248804 | 1.7266102 | 0.0842281 | 1.166829 | 0.0274545 | 1.5453153 |
| 812 | 6.042633 | -5.4 | 29.16 | 7 | 49 | 3 | 5.241207 | 0.8014259 | 0.0815466 | 1.167832 | 0.0056933 | 0.7162279 |
| 84 | 5.669881 | -3.8 | 14.44 | 7 | 49 | 3 | 5.143628 | 0.5262528 | 0.0814274 | 1.167988 | 0.0024506 | 0.4702774 |
| 761 | 5.669881 | -3.8 | 14.44 | 7 | 49 | 3 | 5.143628 | 0.5262528 | 0.0814274 | 1.167988 | 0.0024506 | 0.4702774 |
| 446 | 3.688880 | 10.8 | 116.64 | 7 | 49 | 2 | 5.281918 | -1.5930382 | 0.0801917 | 1.167024 | 0.0220562 | -1.4226366 |
| 500 | 3.912023 | 23.1 | 533.61 | 4 | 16 | 2 | 5.630969 | -1.7189460 | 0.0571116 | 1.166877 | 0.0174049 | -1.5161721 |
| 1116 | 4.499810 | 21.8 | 475.24 | 3 | 9 | 2 | 5.470710 | -0.9709003 | 0.0447326 | 1.167719 | 0.0042371 | -0.8508022 |
| 733 | 6.327937 | -1.0 | 1.00 | 6 | 36 | 1 | 5.813870 | 0.5140673 | 0.0403140 | 1.167998 | 0.0010607 | 0.4494401 |
| 813 | 4.812184 | 0.4 | 0.16 | 6 | 36 | 8 | 5.593501 | -0.7813167 | 0.0380738 | 1.167857 | 0.0023032 | -0.6822957 |
| 210 | 4.663439 | 20.9 | 436.81 | 3 | 9 | 2 | 5.456029 | -0.7925905 | 0.0377796 | 1.167850 | 0.0023504 | -0.6920349 |
Réponse: Beaucoup de parité 8, production, race et cellcount assez variés. En fait, être une 8ième lactation, peu importe le niveau des autres prédicteurs, semble être une combinaison de prédicteurs inusitée.
10.4. Vérifiez maintenant les 10 observations les plus influentes. Ont-elles quelque chose en commun?
diag_cook <- diag[order(-diag$.cooksd),]
influent <- head(diag_cook, 10)| .rownames | log_cell | kgmilk_ct | kgmilk_ct_sq | parity_ct | parity_ct_sq | breed | .fitted | .resid | .hat | .sigma | .cooksd | .std.resid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 445 | 6.975414 | 14.0 | 196.00 | 7 | 49 | 2 | 5.248804 | 1.726610 | 0.0842281 | 1.166829 | 0.0274545 | 1.545315 |
| 446 | 3.688880 | 10.8 | 116.64 | 7 | 49 | 2 | 5.281918 | -1.593038 | 0.0801917 | 1.167024 | 0.0220562 | -1.422637 |
| 214 | 7.634821 | 20.2 | 408.04 | 2 | 4 | 2 | 5.192483 | 2.442337 | 0.0341968 | 1.165683 | 0.0200522 | 2.128520 |
| 874 | 7.903966 | 9.8 | 96.04 | 6 | 36 | 2 | 5.520732 | 2.383233 | 0.0344921 | 1.165798 | 0.0192701 | 2.077328 |
| 500 | 3.912023 | 23.1 | 533.61 | 4 | 16 | 2 | 5.630969 | -1.718946 | 0.0571116 | 1.166877 | 0.0174049 | -1.516172 |
| 916 | 8.984318 | -14.0 | 196.00 | 0 | 0 | 2 | 5.629210 | 3.355108 | 0.0154246 | 1.163616 | 0.0164238 | 2.895999 |
| 488 | 8.999619 | 1.9 | 3.61 | 5 | 25 | 2 | 5.859827 | 3.139793 | 0.0143365 | 1.164179 | 0.0133392 | 2.708651 |
| 880 | 6.853299 | 18.8 | 353.44 | 2 | 4 | 8 | 4.948457 | 1.904842 | 0.0306928 | 1.166638 | 0.0108686 | 1.657084 |
| 1078 | 8.214465 | 0.0 | 0.00 | 0 | 0 | 1 | 4.599325 | 3.615140 | 0.0083997 | 1.162928 | 0.0102372 | 3.109376 |
| 1080 | 3.850148 | 11.4 | 129.96 | 6 | 36 | 2 | 5.495597 | -1.645449 | 0.0354268 | 1.167005 | 0.0094531 | -1.434938 |
Réponse: Il y a peu d’observations influentes et on voit difficilement un profil type en termes de parité, production, race (beaucoup de Holstein, mais c’est aussi la race la plus fréquente dans le jeu de données) ou de CCS.
- Présentation des résultats.
11.1. Présentez les résultats de votre modèle dans une table que vous pourriez soumettre dans une publication scientifique.
#Le package jtools et la fonction summ permettent de générer des tables de résultats un peu plus attrayantes que la fonction summary
library(jtools)
j <- summ(model_final2,
confint = TRUE) #Nous créons un objet j qui contiendra différents éléments. Ici nous avons demandé d'utiliser les IC95 (plutôt que les erreur-types).
j$coeftable #L'élément de j qui se nomme coeftable contient les coefficients, les IC95 (ou les erreur-types), les valeurs de T, las valeurs de P.## Est. 2.5% 97.5% t val. p
## (Intercept) 4.59932473 4.3893612016 4.809288257 42.9812943 4.033724e-237
## kgmilk_ct -0.04728450 -0.0590979988 -0.035471011 -7.8536177 9.609453e-15
## kgmilk_ct_sq 0.00148937 0.0003835792 0.002595162 2.6427669 8.340726e-03
## parity_ct 0.55130050 0.4259755597 0.676625440 8.6313784 2.110234e-17
## parity_ct_sq -0.05950089 -0.0860565013 -0.032945281 -4.3963925 1.207990e-05
## breed2 0.07598558 -0.1379004787 0.289871635 0.6970725 4.859056e-01
## breed3 -0.60044404 -0.8556607831 -0.345227288 -4.6162853 4.369817e-06
## breed8 -0.15291913 -0.3897495271 0.083911261 -1.2669331 2.054491e-01#Dans RMarkdown, pour une sortie plus 'propre', nous pouvons créer une table avec la fonction kable du package knitr.
library(knitr)
Pres_table <- kable(j$coeftable,
caption="Modèle de régression linéaire multiple sur l’effet de la production laitière journalière (en kg) sur le log du comptage des cellules somatiques (CCS) du lait (x1000 cell./ml) basé sur l’étude de 1128 vaches.", #Titre de la table.
digits=3, #Indique le nombre de décimales que nous désirons présenter.
col.names = c('Estimés', 'IC 95 inférieure', 'IC95 supérieure', 'Statistique de T','Valeur de P')
) #Renommer les titres des colonnes
#Le package KableExtra permet d'ajouter des 'footnotes' à la table que nous venons de créer
library(kableExtra)
add_footnote(Pres_table, "L'intercept représente le log du CCS (en 1000 cellules/ml) pour une vache Ayrshire de 1ère lactation et produisant 20kg de lait. Les variables Parity et Breed sont incluses dans le modèle comme facteurs confondants. La race Ayrshire est utilisée comme valeur de référence pour la variable Breed; breed2=Holstein, breed3=Jersey et breed8=autres races.",
notation = "none"
)%>%
kable_styling()| Estimés | IC 95 inférieure | IC95 supérieure | Statistique de T | Valeur de P | |
|---|---|---|---|---|---|
| (Intercept) | 4.599 | 4.389 | 4.809 | 42.981 | 0.000 |
| kgmilk_ct | -0.047 | -0.059 | -0.035 | -7.854 | 0.000 |
| kgmilk_ct_sq | 0.001 | 0.000 | 0.003 | 2.643 | 0.008 |
| parity_ct | 0.551 | 0.426 | 0.677 | 8.631 | 0.000 |
| parity_ct_sq | -0.060 | -0.086 | -0.033 | -4.396 | 0.000 |
| breed2 | 0.076 | -0.138 | 0.290 | 0.697 | 0.486 |
| breed3 | -0.600 | -0.856 | -0.345 | -4.616 | 0.000 |
| breed8 | -0.153 | -0.390 | 0.084 | -1.267 | 0.205 |
| L’intercept représente le log du CCS (en 1000 cellules/ml) pour une vache Ayrshire de 1ère lactation et produisant 20kg de lait. Les variables Parity et Breed sont incluses dans le modèle comme facteurs confondants. La race Ayrshire est utilisée comme valeur de référence pour la variable Breed; breed2=Holstein, breed3=Jersey et breed8=autres races. |
L’effet de la production laitière n’est plus sur l’échelle originale. En plus, la relation entre production et CCS n’est pas linéaire. Tout ça rend votre modèle difficile à interpréter et il faudrait possiblement trouver une manière de rendre l’information plus digestible pour vos lecteurs.
11.2. Vous pourriez présenter comment le CCS varie en fonction de la production laitière pour différents scénarios. Vous pourriez, par exemple, compléter la table suivante, en calculant la valeur prédite pour chaque scénario à l’aide de votre modèle, puis en retransformant ces valeurs sur l’échelle originale:
| Production | 1ère lactation | 2ième lactation | 3ième et plus |
|---|---|---|---|
| 10kg/jour | 185 | 303 | 440 |
| 20kg/jour | 99 | 163 | 236 |
| 30kg/jour | 72 | 118 | 171 |
11.3. Encore mieux : à partir d’une table R contenant les valeurs prédites, retransformez la valeur prédite sur l’échelle originale en créant une nouvelle variable \(CCS=exp(valeur prédite)\). Ensuite, vous pourrez utiliser le package ggplot2 pour représenter dans un graphique nuage de points la relation entre la production laitière (en x) et la valeur prédite de CCS (en y).
C’est plus simple à comprendre ainsi n’est-ce pas?
diag$pred <- exp(diag$.fitted) #Une variable de CCS sur l'échelle originale
diag$kgmilk <- diag$kgmilk_ct+20 #Recréer la variable kgmilk originale
diag$parity <- factor(diag$parity_ct+1) #Recréer la variable parité originale
library(ggplot2)
ggplot(diag,
aes(x=kgmilk, y=pred)
) +
geom_point(aes(colour=parity)) +
labs(x="Production (en kg/j)",
y="CCS (en 1000 cellules/ml)") +
theme_bw() 
Figure 6.30: Valeurs de CCS (par 1000 cell./ml) prédites par le modèle en fonction de la production laitière (en kg/j) et du nombre de lactations.